Completely Randomized Design
Completely Randomised Design (CRD) widely used in Agricultural research … Read more …
Completely Randomized Design (CRD) is a basic experimental design for comparing treatments under homogeneous conditions. CRD assigns treatments randomly to experimental units, such as field plots or plants, ensuring each unit has an equal chance of receiving any treatment. In RAISINS you can perform CRD very easily without writing a single line of code. This tutorial will guide you, how to perform CRD very easily in RAISINS and interpret the results effectively. In addition, you will get tables and plots ready for publication. You can also perform a multivariate analysis including MANOVA and PCA.
Introduction Completely Randomized Design
-
In the 1920s, statistician Ronald A. Fisher
 introduced modern statistical theory. He made significant contributions to the development of the Completely Randomized Design (CRD), which was first used in the early 20th century. Fisher developed this design to enhance agricultural studies, particularly to identify subtle yet significant variations in crop yields under various fertilizer treatments. His novel approach was to prevent bias and enable reliable statistical analysis through analysis of variance (ANOVA) by randomly assigning treatments to experimental units (like land plots).
introduced modern statistical theory. He made significant contributions to the development of the Completely Randomized Design (CRD), which was first used in the early 20th century. Fisher developed this design to enhance agricultural studies, particularly to identify subtle yet significant variations in crop yields under various fertilizer treatments. His novel approach was to prevent bias and enable reliable statistical analysis through analysis of variance (ANOVA) by randomly assigning treatments to experimental units (like land plots).
1 Analysis of experiments
To get started, visit RAISINS www.raisins.live home page and go to Analysis of experiments. Here, you can see different single-factor experimental designs. In this tutorial, we focus on Completely Randomized Design (CRD), as shown in Figure 1.
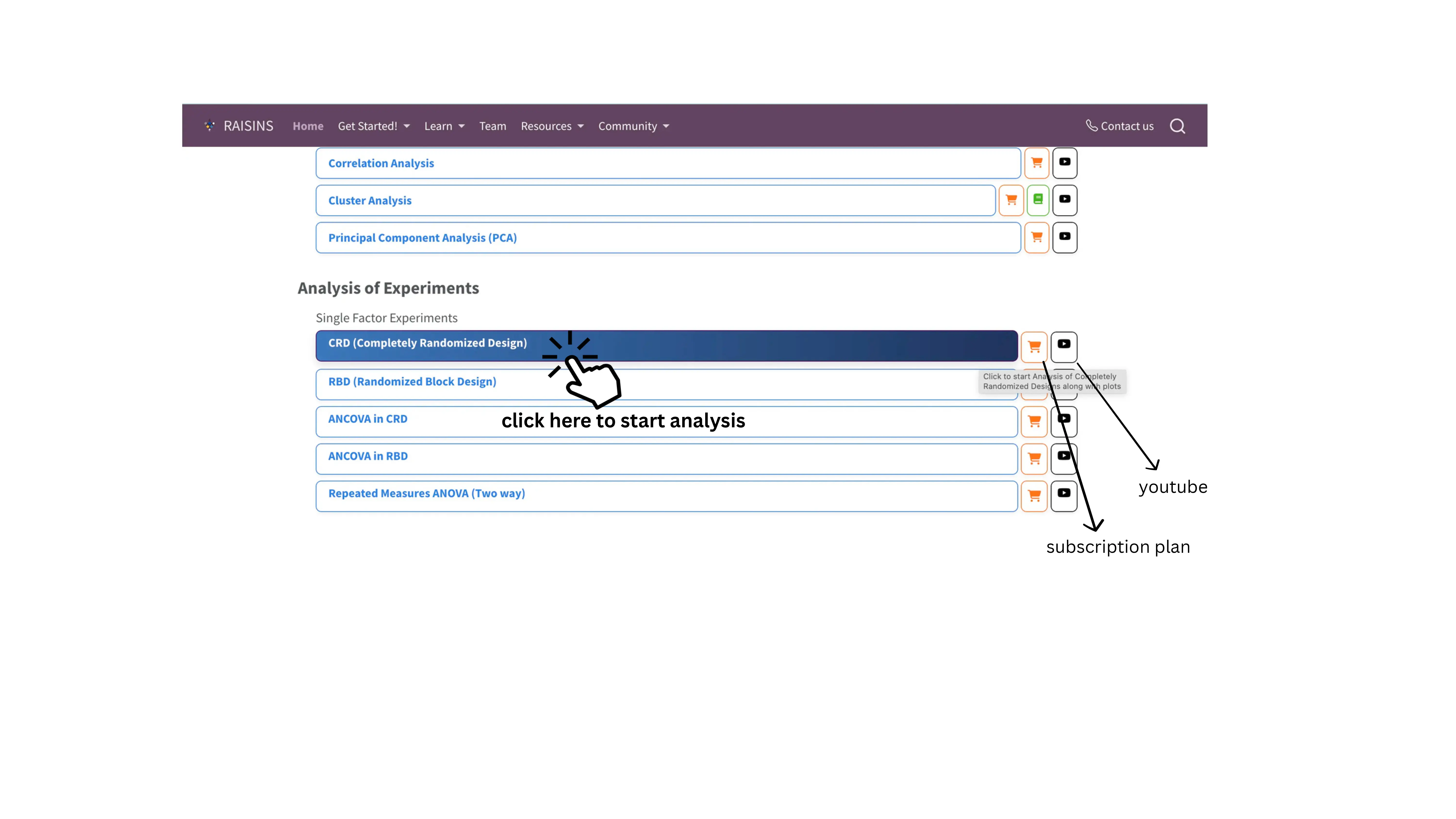
2 Completely Randomized Design (CRD)
A Completely Randomized Design (CRD) is the simplest and most fundamental experimental design used in statistics, where all experimental units are randomly assigned to different treatment levels of a single factor, without any blocking or grouping. CRD is used in controlled settings like lab experiments, greenhouse trials, chemical assays, or biological studies where external variability is low and blocking is unnecessary. It excels in simplicity, providing maximum error degrees of freedom for efficiency with small samples, but unsuitable for heterogeneous field conditions; in such cases, a Randomized Block Design (RBD) is more appropriate.
CRD Layout
Figure 2 visually represents a Completely Randomized Design (CRD) arrangement with four treatments labeled as A, B, C, and D arranged randomly across experimental units.Each square block corresponds to one experimental unit or plot where a treatment is applied.Letters A, B, C, and D represent the four different treatment groups applied to the experimental units randomly and replicated three times.The randomized arrangement inside the grid (3 rows and 4 columns) exemplifies the core principle of CRD, where treatments are assigned entirely at random without restrictions or blocking.The layout shows no pattern by row or column, confirming random allocation, which helps to ensure that uncontrolled variability is minimized by chance.

3 A working example
To make things simple and interesting, we’ll explain CRD analysis step by step using a hypothetical example, so you can clearly see how it works and why it matters.Let’s assume the experiment is conducted in a field. Consider a dataset containing 10 treatments, each representing a distinct mango variety, with three replicates per variety. The treatments(varieties) are named as follows Alphonso, Kesar, Dasheri, Himsagar, Chausa, Badami, Safeda, Bombay_g, Langra, and Totapuri. Observations were recorded for four variables: yield, Obs1, Obs2, and FW.Our aim is to test whether treatments produce statistically significant differences in the response variable using ANOVA. The treatments are evaluated for each variables. The arrangement of the data is shown in the Figure 3 .
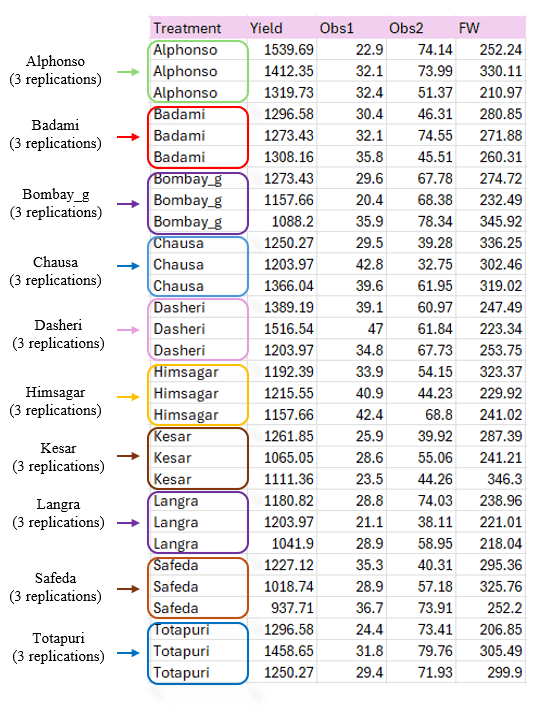
Data organized in MS Excel can be directly uploaded to RAISINS for analysis. For more details on data preparation see Section 4. Two terms that we will use frequently are Treatments and Variables. In our example, the Treatments refer to the varieties, and the Variables are the four traits mentioned earlier - yield, Obs1, Obs2, and FW.
4 How to prepare your data?
Arranging data for uploading in RAISINS is very simple. Prepare your data exactly like the one shown in Figure 3, using a single-sheet Excel file. Make sure no blank rows are left above, and all columns have proper names. That’s it - your file is ready to upload.
Still if you have doubt, see Figure 4 .
To prepare your dataset for analysis in RAISINS, you have two options:
Creating dataset in MS Excel
Creating your dataset directly within the RAISINS app
5 CRD analysis tab explained
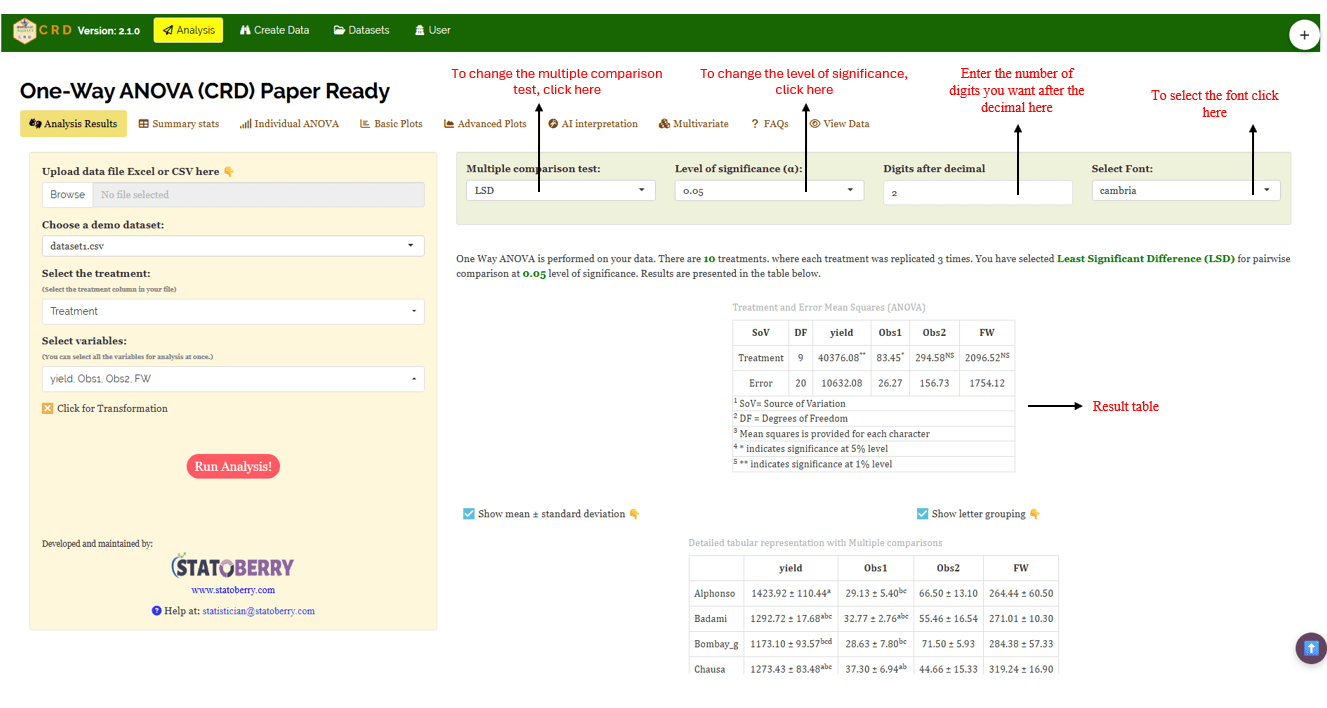
In Figure 5 , you can see the detailed view of the Analysis tab, along with explanations of what each option does. This section helps you to understand the purpose of every settings, so you can select the most appropriate ones for your data and analysis. Now, upload the prepared file by clicking Browse in the sidebar of the Analysis tab. When the file is uploaded, options to select the Treatment and variables will appear. Select the appropriate column under treatments and variables. Once you click the Run Analysis button, all relevant results and outputs appear instantly leaving no room for confusion.
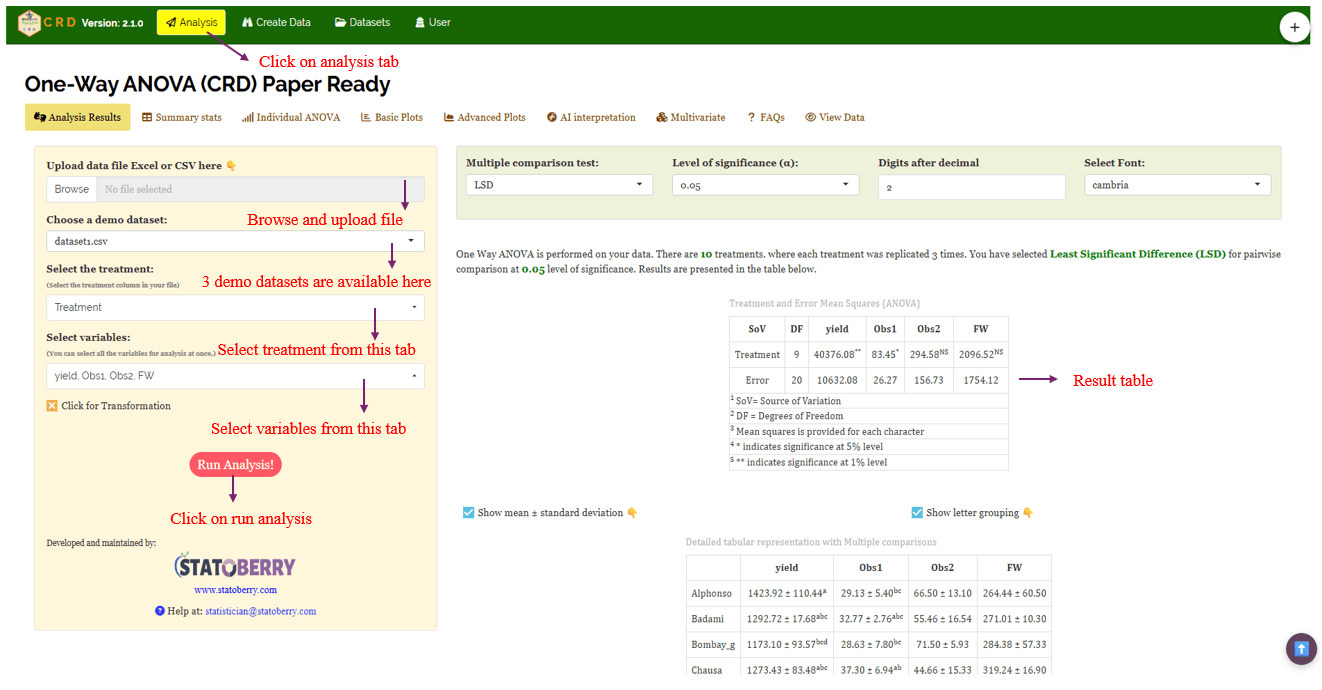
For some data, when there are large number of zeros/ discrete values/ when the observed variables are not normally distributed, we need to do transformation on the dataset (Section 6) . Here, RAISINS provide inbuilt transformation option.
6 Transformation
Log, square root, and arcsine transformations are often used in CRD analysis to make data more normal and reduce uneven variation. Researchers can use these transformations when analyzing experimental data in RAISINS as shown in Figure 6.
Logarithmic transformation is a mathematical procedure used to convert a skewed distribution into a more symmetrical one by replacing each data point (x) with its logarithm. This technique is specifically applied to positive, continuous data where the variance is proportional to the mean, a relationship common in phenomena that exhibit multiplicative or exponential growth.
Square root transformation is a statistical method used to stabilize variance and reduce right-skewness by replacing each data point (x) with its square root. It is primarily applied to non-negative, discrete “count” data such as those following a Poisson distribution, where the variance of the data tends to increase in proportion to the mean. By compressing the upper end of the scale more significantly than the lower end, this transformation brings the data closer to a normal distribution, satisfying the homoscedasticity requirements of many parametric statistical tests.
Arcsine transformation (also known as the angular transformation) is a mathematical technique specifically designed for data expressed as proportions or percentages bounded between 0 and 1. By taking the inverse sine of the square root of the proportion, this transformation stretches the ends of the distribution near 0 and 1, where variance is naturally small. It is primarily used to achieve homoscedasticity in binomial data.
After choosing the appropriate transformation proceed to Section 7 for analysis.
7 Analysis results
Once your dataset is uploaded, cick on Run Analysis, one-way ANOVA will be performed. Analysis of Variance (ANOVA) is a statistical technique used to test the significance of differences among population means by partitioning total variation into treatment and error components and comparing them using the F-test (see Figure 7 ).
Table 1 ANOVA summary
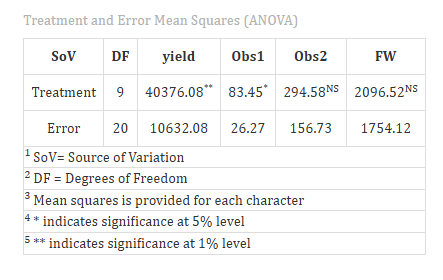
ANOVA table
In a Completely Randomised Design (CRD), the analysis of variance (ANOVA) is used to test whether there are significant differences among the treatment means. The test statistic-F, follows an F distribution with two degrees of freedom: the numerator degrees of freedom (k-1), where k is the number of treatments, and the denominator degrees of freedom (N-k), where N is the total number of experimental units. To check whether the null hypothesis (all treatment means are equal)can be rejected or not, the calculated F value from the ANOVA table is compared with the critical F value obtained from F distribution table based on the degrees of freedom and the chosen significance level (α).
Significance is indicated by an asterisk ( * ) for the 5% level and two asterisks (** ) for the 1% level of significance, displayed as superscripts for each corresponding F stat in the table.
If the computed F value exceeds the critical value, the null hypothesis is rejected, indicating that at least one treatment mean differs significantly from the others. However, ANOVA alone does not indicate which specific treatments differ. Therefore, if a significant difference is detected, multiple comparison tests such as Fisher’s LSD, Tukey’s HSD or DMRT are performed to make pairwise comparisons between treatments and identify precisely where the differences exist.
7.1 Interpretation from Figure 7
The ANOVA result show that the treatment mean square (40376.08) is much larger than the error mean square (10632.08), producing F-ratio of approximately 3.79, with 9 degrees of freedom for treatment and 20 for error, this F-value is statistically significant at the 1% level. This indicates that the variation in yield among treatments is highly unlikely to be due to random chance, and the null hypothesis (no treatment effect) can be rejected.
In practical terms, the treatments exerted a strong influence on yield performance, meaning that at least one treatment differs meaningfully from the others. The presence of such significant differences suggests that further post-hoc tests (such as Tukey’s HSD or LSD) would be appropriate to identify which specific treatments contributed to the observed variation.
Section 8 provide detailed information on the multiple comparison test (Post-hoc test).
Table 2: Detailed tabular representation with multiple comparisons
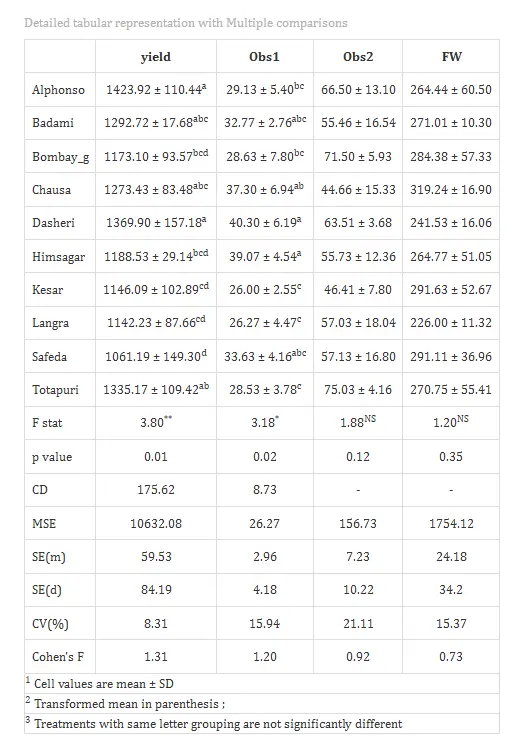
Overview of ANOVA Results and Interpretation
- Treatments and Response Variables
Treatments: The independent variable or specific category (e.g., mango variety) being tested to determine its influence on the results.
Response Variable: The dependent variable or specific measurement (e.g., weight or yield) recorded to evaluate the performance of the treatments.
- Multiple Comparisons
Post-hoc Grouping: A method of using letters (a, b, c) to categorize means. Items sharing the same letter are statistically similar, while those with different letters are significantly different.
- ANOVA Summary
F stat: A numerical value that compares the variance between different groups to the variance within those groups; it determines if the overall differences are statistically significant.
p value: The probability that the observed differences occurred by random chance. A value typically indicates that the results are statistically significant.
- Critical Difference (CD) and Error Estimates
Critical Difference (CD): The minimum mathematical gap required between two means to declare them “significantly different” at a specific confidence level.
Standard Error (SE): A measure of the accuracy of a sample mean compared to the true population mean; it indicates how much the mean might fluctuate.
Mean Square Error (MSE): The average of the squared differences between observed values and the predicted mean; it represents the “noise” or unexplained error in the experiment.
Coefficient of Variation (CV%): A percentage that shows the level of dispersion in the data. A lower CV indicates higher precision and reliability in the experimental measurements.
Cohen’s F: A standardized measure of effect size that describes the magnitude of the experimental effect, regardless of the sample size.
7.2 Interpretation from Figure 8
Treatments are then grouped using letters like “a”, “b”, “c”, etc., to indicate statistical similarity. Overlapping of grouping letters (e.g., ab/ bc) indicates that the absolute difference between treatment means is less than the critical difference at the chosen level of significance, implying statistical similarity (on par). For example, if both Alphonso and Badami are labeled “a”, their yields are statistically similar at 5% significance level. Treatments with no common letters (e.g., a and c) differ significantly, providing a clear visual summary of treatment comparisons.
For characters exhibiting significant treatment effects, pairwise comparisons of treatment means were conducted using the Least Significant Difference (LSD) test. The LSD test provides the critical difference (CD) value, which was used to determine significant differences between pairs of treatment means. Based on these comparisons, letter groupings were assigned to each treatment and presented as superscripts. Treatments sharing at least one common letter within a character were considered not significantly different (statistically on par).
In our example for the character yield, Alphonso recorded the highest mean value (1423.92 ± 110.44), whereas Safeda exhibited the lowest mean (1061.19 ± 149.30). Alphonso was statistically at par with Badami, Chausa, Dasheri, and Totapuri, as indicated by common letter groupings, i.e you can see from Table 2. Similarly, Safeda was statistically at par with Bombay green, Himsagar, Kesar, and Langra.
The Cohen’s f values in the table represent the effect size and quantify the magnitude of treatment effects. Values less than 0.10 indicate a very small effect, below 0.25 indicate a small effect, below 0.40 indicate a medium effect, and values of 0.40 or higher indicate a large effect. The observed effect size for yield should therefore be interpreted as substantial and biologically meaningful, confirming that treatment differences are not only statistically significant but also practically relevant to the study.
8 Multiple comparison tests
What is Post-hoc test?
-
Post-hoc test is a follow-up analysis, performed after finding a significant result in an overall statistical test (like ANOVA). It’s purpose is to identify exactly which groups or treatments differ from each other. In other words, it helps to pinpoint where the differences lie between multiple groups, when the initial test shows that not all groups are the same.
After obtaining a significant F-value in ANOVA under CRD, multiple comparison tests are employed to identify which treatment means differ significantly. Commonly used post hoc tests include Least Significant Difference (LSD), Tukey’s Honest Significant Difference (HSD), and Duncan’s Multiple Range Test (DMRT), each differing in their level of error control and suitability depending on the number of treatments and experimental conditions (see Figure 9).
Post-hoc test
When the ANOVA in a Completely Randomised Design (CRD) is significant, the following post hoc tests are commonly used for pairwise comparisons: Tukey’s Honestly Significant Difference (HSD) test, and Fisher’s Least Significant Difference (LSD) test. These tests help identify which specific treatment means differ from each other, addressing the limitation of ANOVA in not indicating the exact sources of variation.
LSD (Least Significant Difference) Test
The Least Significant Difference (LSD) test is a post-hoc statistical procedure used in the context of a Completely Randomized Design (CRD) to identify which specific treatment means differ significantly after a one-way ANOVA has indicated an overall significant effect. When the ANOVA F-test rejects the null hypothesis, it implies that at least one treatment mean is different, but it does not specify which pairs differ. The LSD test addresses this by performing pairwise comparisons between treatment means using a critical difference threshold.
The LSD is calculated as \[\text{LSD} = t_{\alpha/2, \, df_{\text{error}}} \sqrt{\frac{2 \ \text{MSE}}{n}}\]
where, t₍α/2, dfₑᵣᵣₒᵣ₎ is the critical t-value at the chosen significance level (e.g., 0.05), MSE is the mean square error from the ANOVA, and n is the number of replications per treatment under equal sample sizes. Any absolute difference between two treatment means exceeding this LSD value is declared statistically significant. The test assumes homogeneity of variances and is most valid when the overall F-test is significant, as it uses a pooled error term from all treatments, making it more powerful but also more prone to Type I errors when multiple comparisons are made without adjustment. The LSD test is simple and sensitive,therefore it should be applied cautiously, preferably for planned comparisons or nearby means in ordered data, because using it freely can increase the chance of false results.
Tukey’s Honestly Significant Difference (HSD)
Tukey’s test helps you find out exactly which pairs of treatment means differ significantly. The main idea is that Tukey’s HSD compares all possible pairs of treatment means while controlling the overall Type I error rate, so you avoid false positives when making multiple comparisons. It calculates a critical value based on the number of treatments, degrees of freedom for error (from ANOVA), and the mean square error. In CRD, this method works well because treatments are assigned completely at random and the error variance is assumed homogeneous. Tukey’s HSD uses the within-group variance from ANOVA (Mean Square Error) and the number of replicates per treatment to assess whether the difference between any two means is “honestly significant.”
Duncan’s Multiple Range Test (DMRT)
After confirming significant overall differences via ANOVA, DMRT ranks the treatment means and calculates critical differences using the studentized range statistic (Q) and the standard error based on error variance from ANOVA. For each pair of means, the observed mean difference is compared to a calculated critical value that increases with the number of means being compared, making DMRT more powerful than simpler tests like LSD. If the difference exceeds the critical threshold, the means are considered significantly different; otherwise, they are grouped together. This systematic and sequential approach provides clear groupings of treatments, ensuring that the probability of discovering real differences is maximized, which is why DMRT has gained popularity in agricultural research.
Which Post-hoc test to use?
The choice of the post-hoc test completely relies on the researcher.
LSD is used for pairwise comparison of treatment means after a significant ANOVA in CRD. It is most suitable when the number of treatments is small and comparisons are limited, offering high sensitivity to detect differences, but it may increase Type I error when many treatments are compared.In agricultural experiments LSD is the most commonly used.
Tukey’s HSD is preferred when there are four or more treatments in a balanced CRD. It compares all possible treatment pairs while strictly controlling the family-wise error (the probability of making at least one false positive (Type I error) when you run multiple hypothesis tests at the same time) rate, making it a conservative and reliable method for multiple comparisons.
DMRT is commonly used in agricultural experiments with several treatments. It ranks treatment means step-wise and detects more significant differences than Tukey HSD, though it is less conservative and carries a higher risk of Type I error.
In the example for those characters, a pairwise comparison was performed to identify significant differences between treatments using Least Significant Difference (LSD) test.
9 Summary stats
If you need to know about the detailed values of the various statistical metrices of treatments, move to Summary stats under the Analysis.
Table 3: Summary statistics
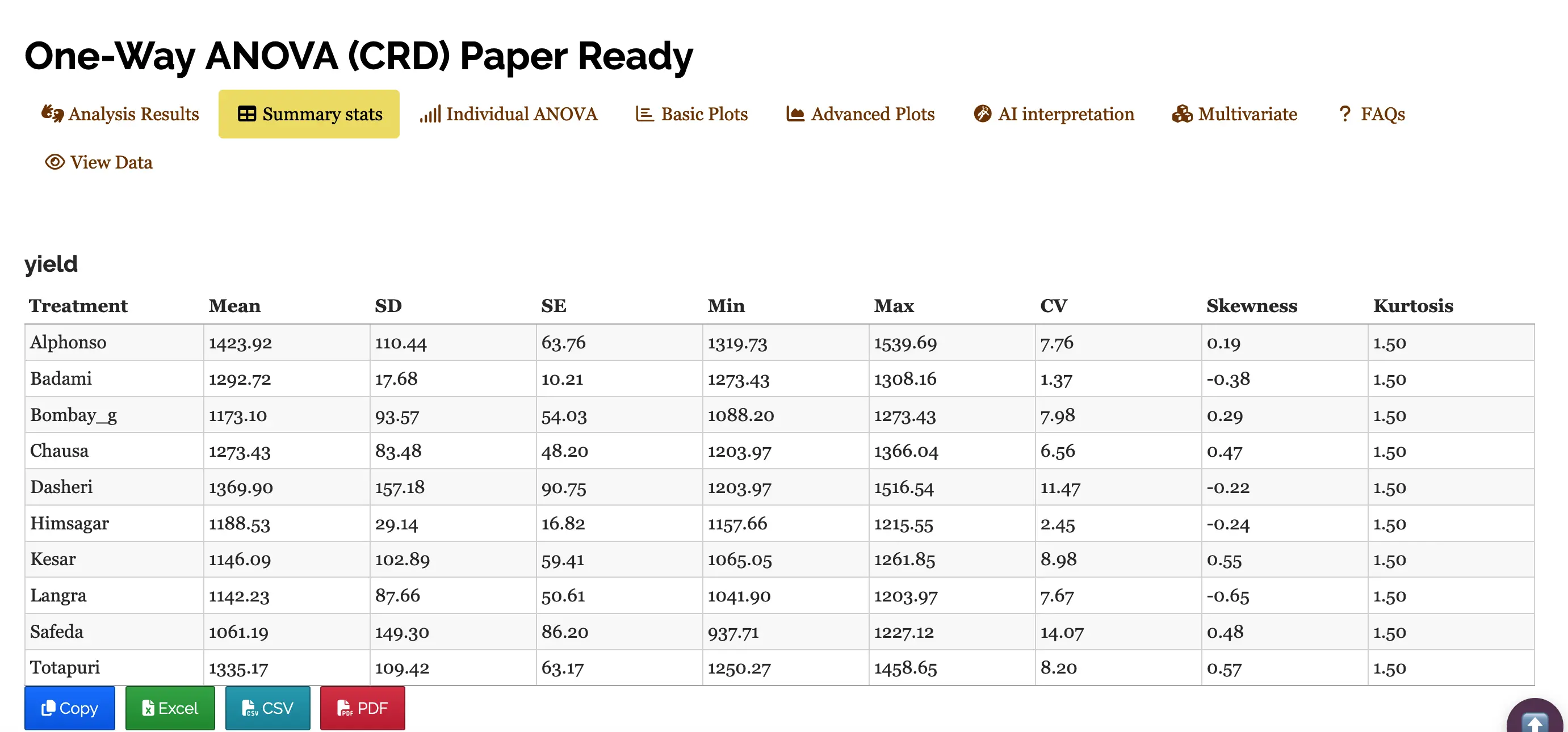
Table parameters
Mean The arithmetic average of all observations within a treatment. It represents the “typical” yield for that specific variety.
SD (Standard Deviation) A measure of the amount of variation or dispersion of a set of values. A low SD indicates that the data points tend to be very close to the mean.
SE (Standard Error) Specifically the Standard Error of the Mean. It estimates how far the sample mean is likely to be from the true population mean. It is calculated as \[SE = \frac{\text{Standard deviation (SD)}}{\sqrt {n}}*100\],where n is the number of observations.
Min / Max The lowest and highest recorded yield values within that specific variety group.
CV (Coefficient of Variation) The ratio of the standard deviation to the mean, expressed as a percentage \[CV = \frac{\text{Standard deviation (SD)}}{\text{Mean}}*100\]
It allows you to compare the variability between groups with different scales.
Skewness A measure of the asymmetry of the probability distribution. Positive value: Data is skewed to the right (long tail on the right). Negative value: Data is skewed to the left (long tail on the left).
Kurtosis A measure of the “tailedness” of the distribution. It describes how much of the data is concentrated in the tails versus the peak. A standard normal distribution has a kurtosis of 3; values lower than that indicate a flatter peak.
9.1 Interpretations from Figure 10
The table presents a summary of yield performance across ten treatments, likely representing different mango varieties. Among them, Alphonso recorded the highest average yield (1423.92), followed by Dasheri and Totapuri, while Safeda had the lowest mean yield (1061.19).Varieties like Badami and Himsagar showed low variability in yield, indicated by their small standard deviations and low coefficients of variation (CV), suggesting consistent performance. In contrast, Safeda and Dasheri had higher CVs, pointing to greater fluctuation in yield. Skewness values show that most treatments had slightly asymmetric yield distributions, some leaning toward higher values (positively skewed) and others toward lower (negatively skewed). All treatments had a kurtosis of 1.5, indicating a relatively flat distribution compared to the normal curve.
10 Individual ANOVA
If the user want to get individual ANOVA table for each variable click on Individual ANOVA in the Analysis.
The significance of the treatment can be measured using F-test and p value as in Figure 11.
Table 4: ANOVA table for yield
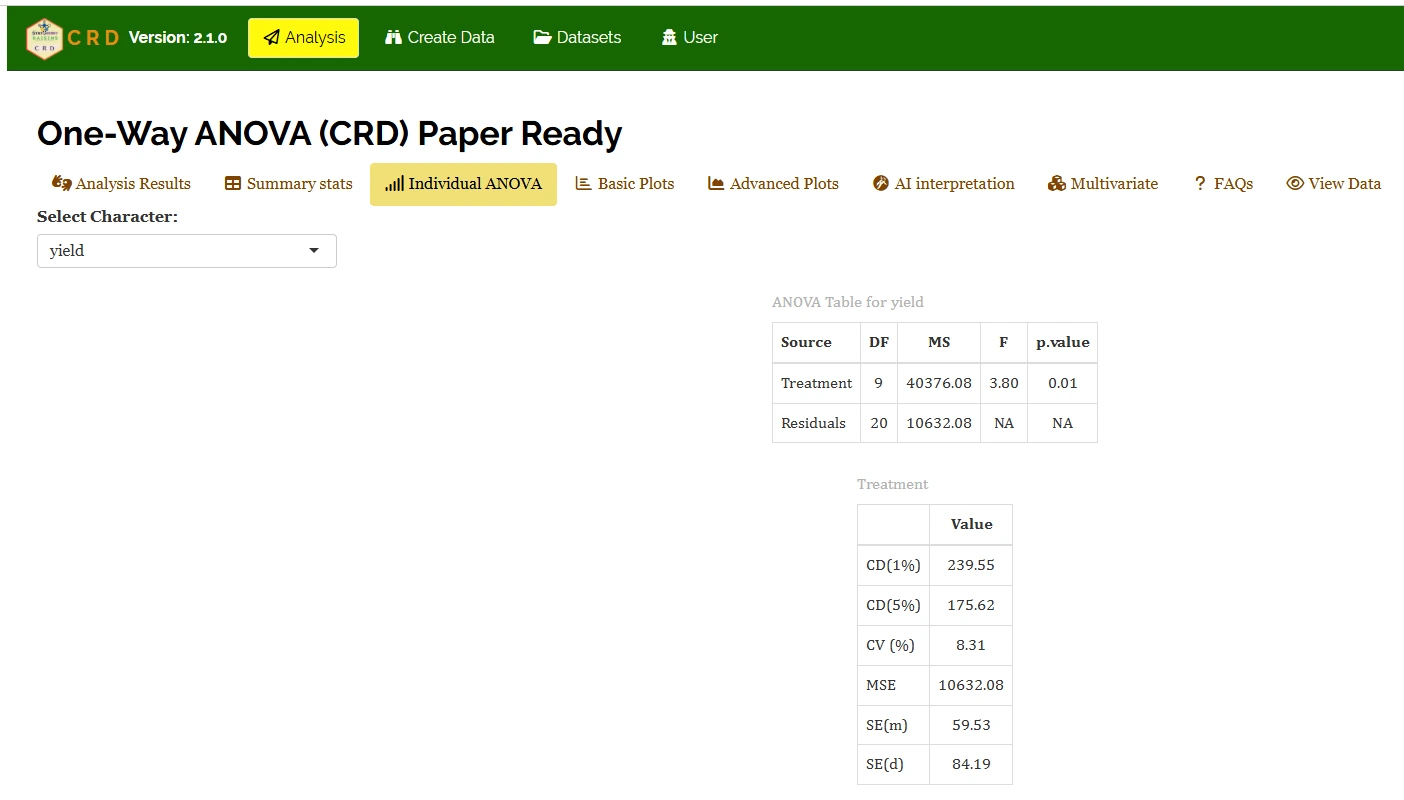
Table parameters
Critical Difference (CD)
The minimum difference required between any two treatment means to consider them significantly different from each other.
In your table: At a 1% level (239.55), you are 99% confident in the difference. At a 5% level (175.62), you are 95% confident. You use these values for “mean separation” (e.g., Duncan’s test or Tukey’s).
Coefficient of Variation (CV (%))
A relative measure of dispersion that expresses the standard deviation as a percentage of the mean. \[CV = \frac{\text{Standard deviation (SD)}}{\text{Mean}}*100 \tag{1}\]
In your table: 8.31% indicates the experimental error is low, which is excellent for field trials.
Mean Square Error(MSE)
The Residual Mean sum of Squares from the ANOVA table. It represents the “noise” or unexplained variance in the experiment.
In your table: 10632.08, this value is used to calculate all the SE and CD values below it.
Standard Error of Mean(SE(m))
Measures how much the sample mean of a treatment is likely to vary from the true population mean. \[ SE(m)=\sqrt{MSE / r}\] Where, r is the number of replications.
Standard Error of Difference (SE(d))
The standard error associated with the difference between two treatment means. \[ SE(d)=\sqrt{2 \times MSE / r}\] It is the foundation for calculating the CD value.
10.1 Interpretation from Figure 11
It shows that the treatment mean square (40376.08) is much higher than the error mean square (10632.08), resulting in a calculated F-value of 3.80, which is significant at the 1% level (p = 0.01), indicating that treatments differ significantly in their effect on yield. The mean square error (10632.08) represents random variation and is used to compute precision measures such as standard error of a treatment mean, SE(m) = 59.53 and standard error of difference between two treatment means,SE(d) = 84.19, while the critical differences of 175.62 at 5% and 239.55 at 1% indicate the minimum difference required between two treatment means for significance. The coefficient of variation (8.31%) is low, showing good experimental precision and reliability of the results.
Table 5: summary statistics
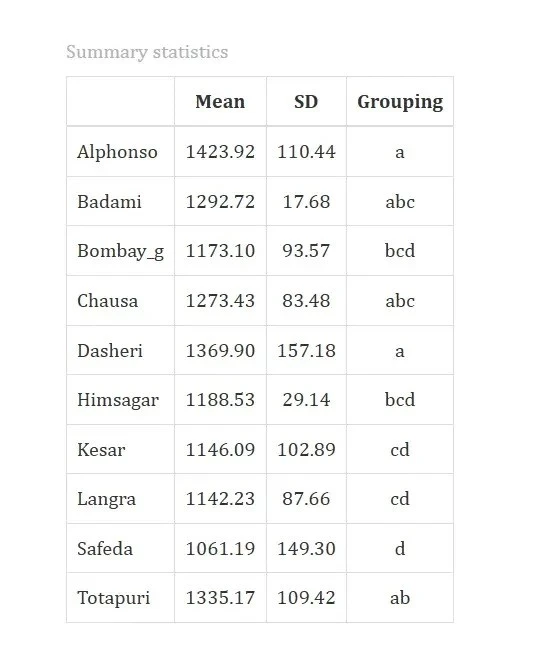
10.2 Interpretation from Figure 12
Table compares different mango varieties based on their average values (Mean), variation (Standard Deviation or SD), and how they are grouped statistically.Alphonso and Dasheri mangoes have the highest average values, showing top performance. Safeda ranks lowest. Varieties are grouped based on statistical similarity, those sharing letters (“abc” or “cd”) are not significantly different. This helps identify which mango types truly differ and which are alike.
11 Basic plots
RAISINS is designed for a smooth and hassle-free experience. Once you click the Run Analysis button, all relevant results and outputs appear instantly-leaving no room for confusion. We’ve ensured that every possible plot related to the Completely Randomisd Design is readily available. Simply click on the Basic Plots tab to view them (See Figure 13). Each plot comes with a gear icon at the top-left corner, allowing you to customize its appearance. You can also download these plots in high-quality PNG format (300 dpi),JPEG,TIFF,PDF and SVG for use in reports or presentations.
11.1 Customizing plots
RAISINS provides user various customization features for the plots to enhance the visualization according to the requirement of the user. Click on Figure 13 to get a clear idea on the customizing features.
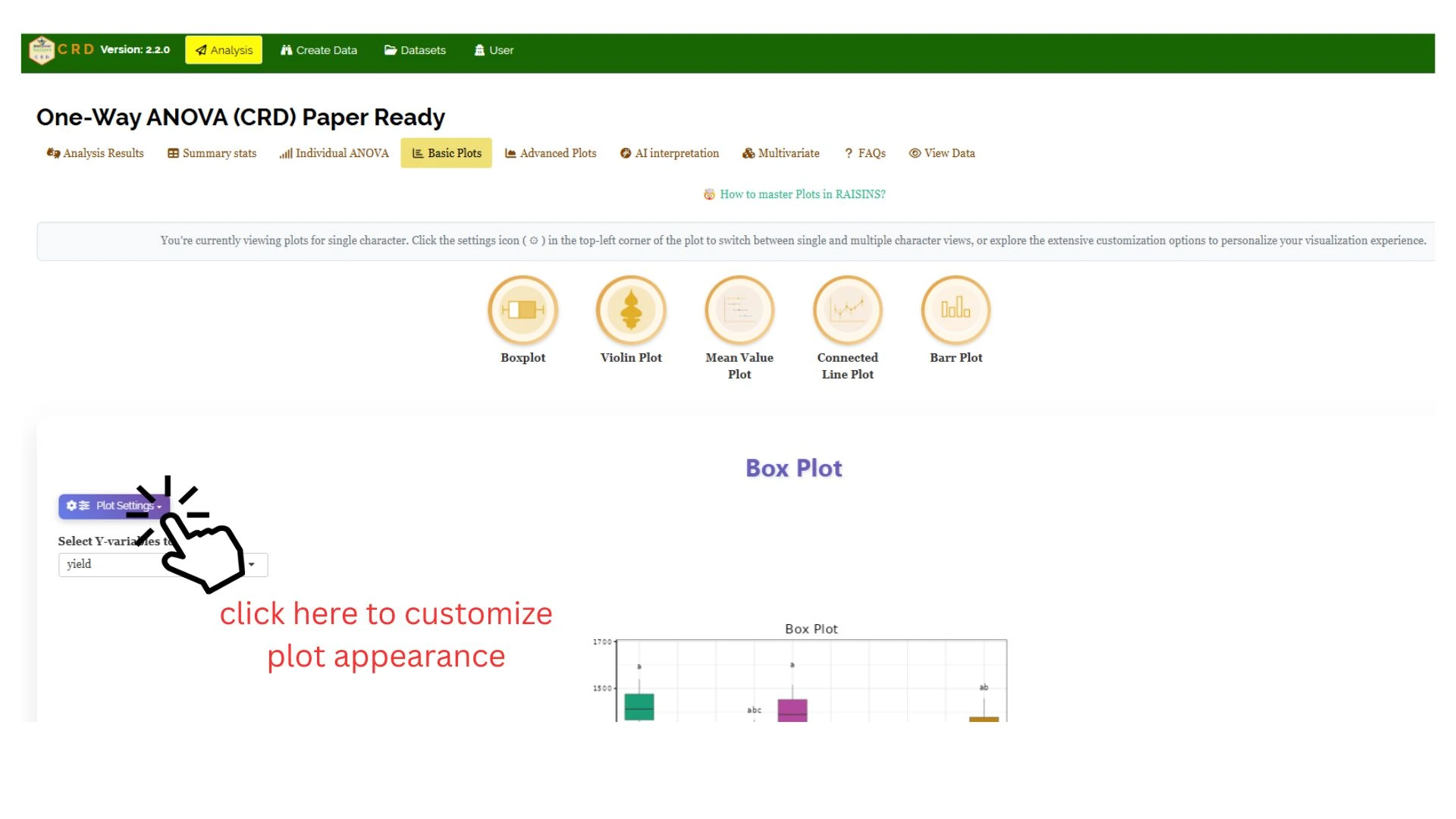
From Figure 14 to Figure 18, you can see the different types of plots available in RAISINS. Each one is visually illustrated and accompanied by a clear, insightful description below, making it easy to understand.
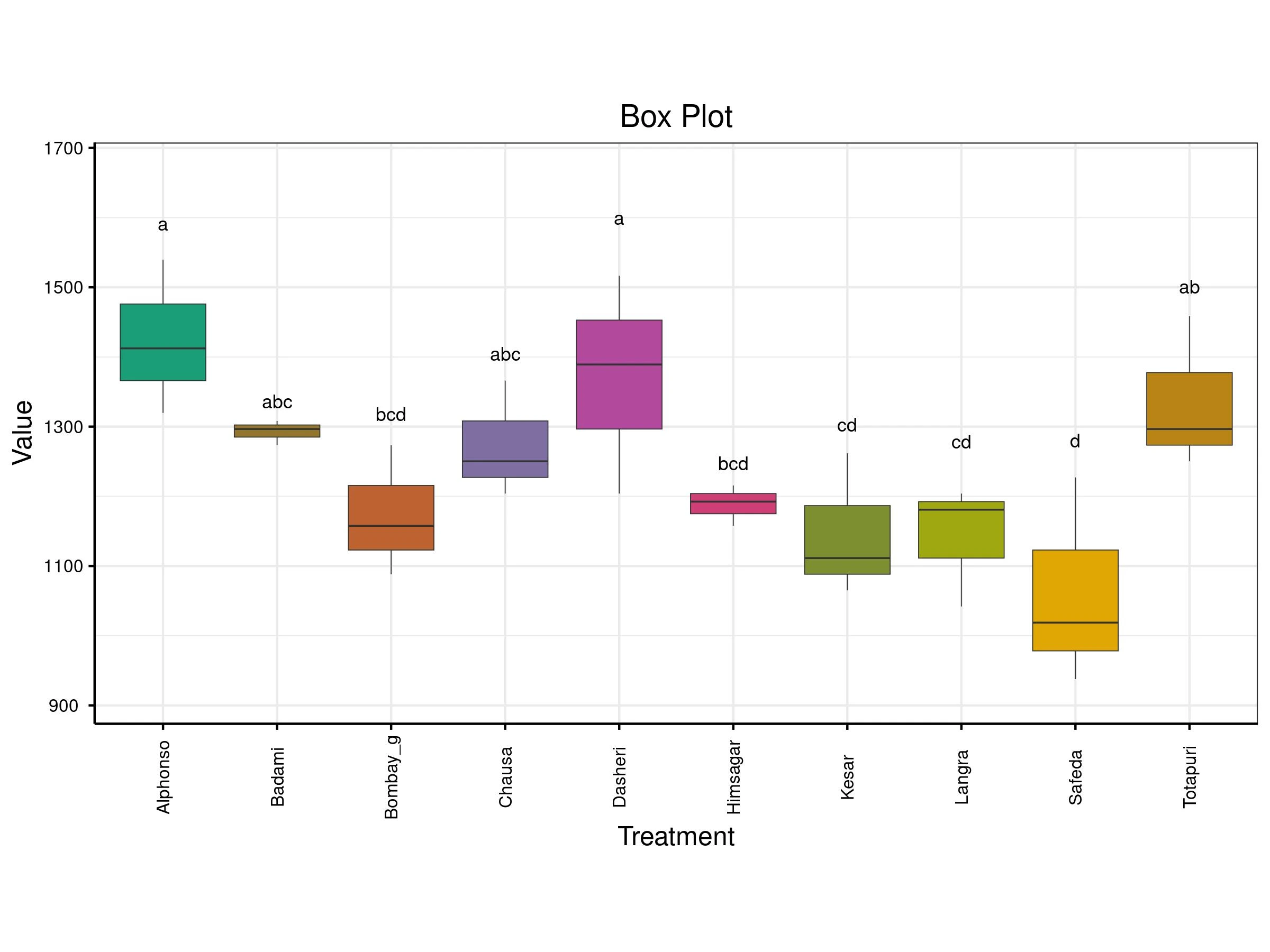
A box plot compares the distribution of values across different treatments. Each colored box represents a treatment and shows key statistics: the median (middle line), the interquartile range (the box itself), and potential outliers (points outside the whiskers). The vertical axis shows the value range, while the horizontal axis lists the treatments. Letters above each box indicate statistical groupings treatments sharing letters are statistically similar, while those with different letters are significantly different.
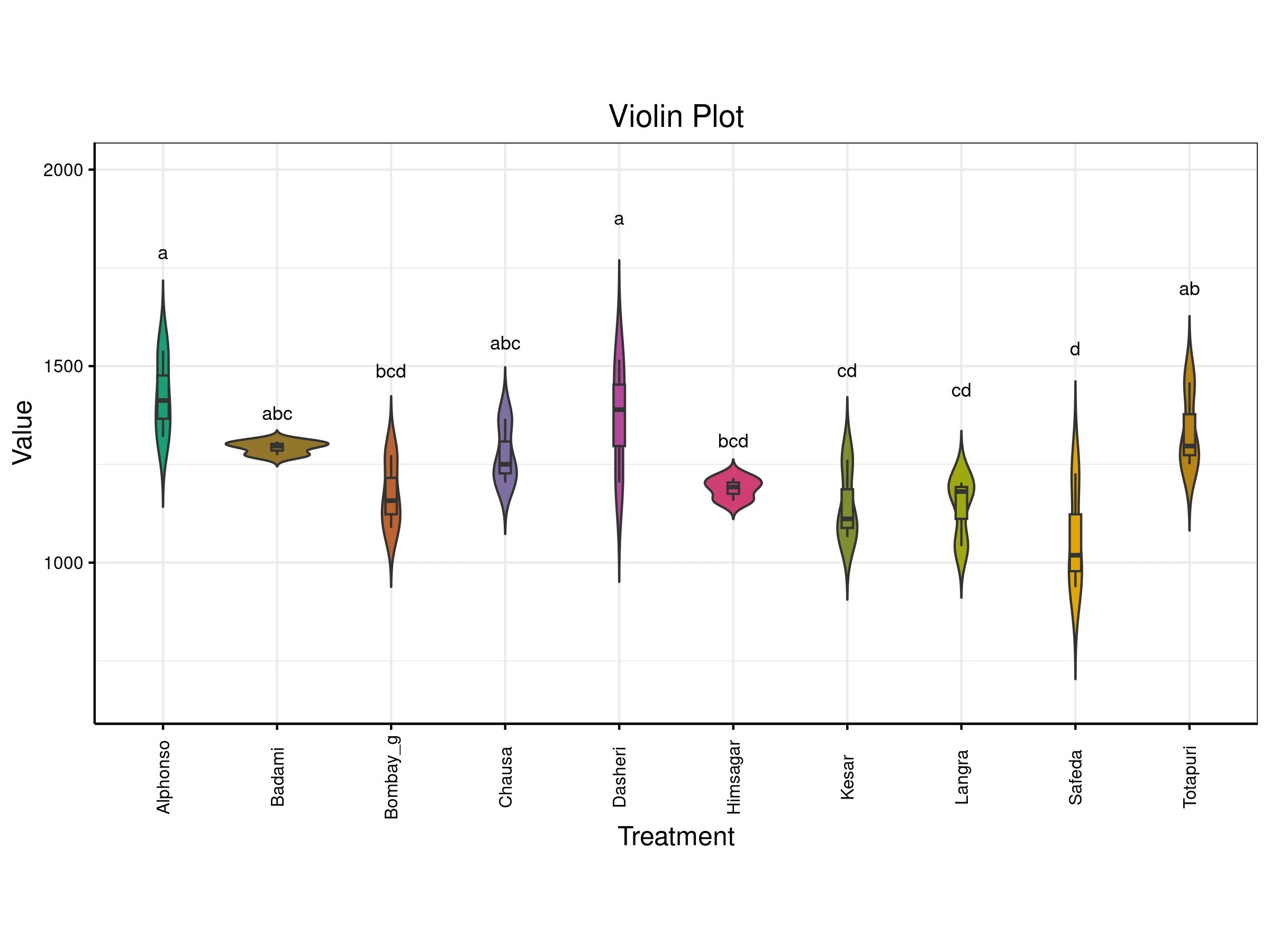
A violin plot compares the distribution of values across different treatments. Each treatment (like a mango variety) is shown as a violin shape that reflects how the data is spread wider sections mean more data points at that value. Inside each violin is a box plot showing the median and interquartile range. The letters above each plot indicate statistical groupings: treatments sharing letters are statistically similar, while those with different letters are significantly different. This plot helps you see not just the average values, but also how consistent or variable each treatment is.
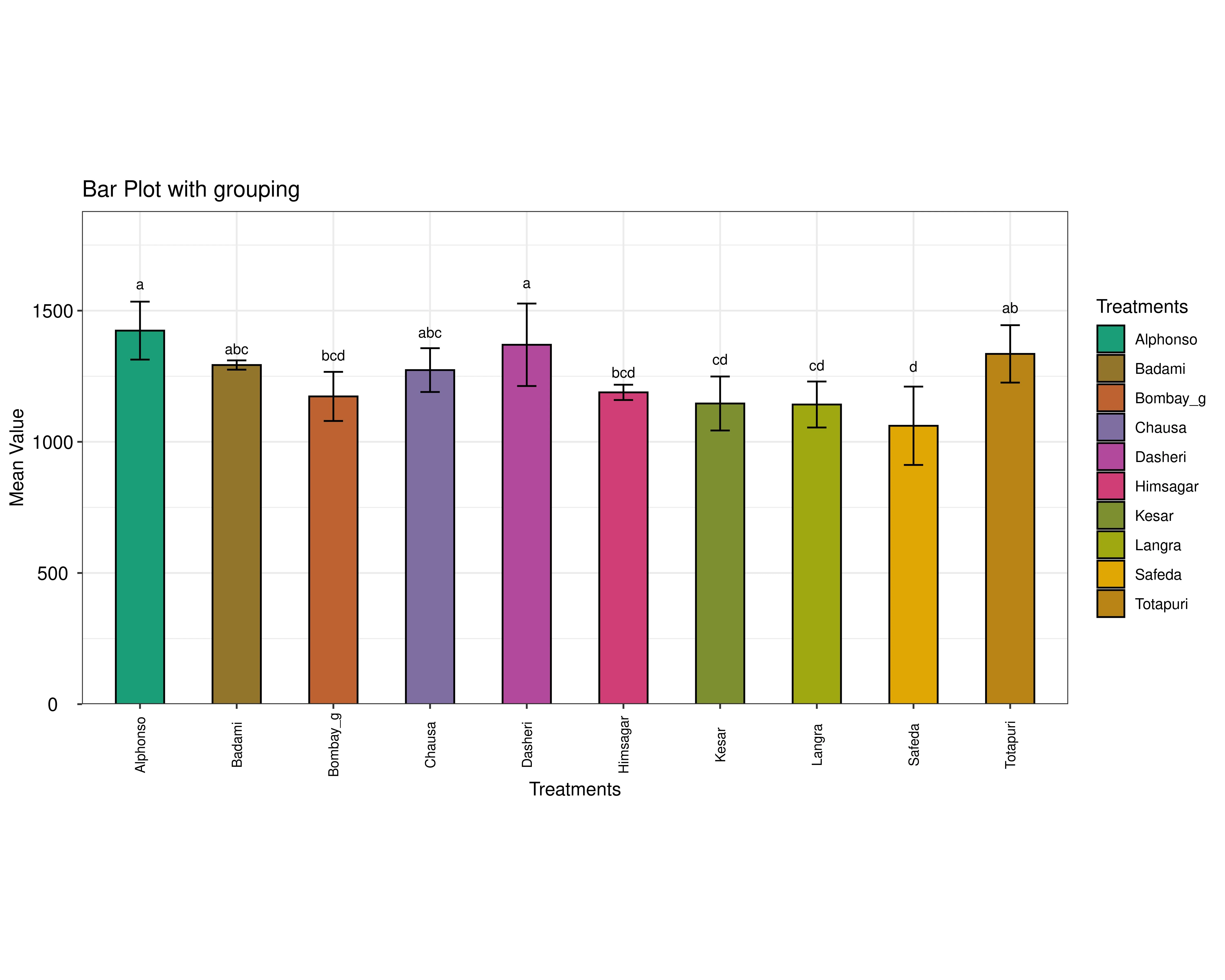
A Bar plot compares the average values of different treatments, with error bars showing variability. The letters above each bar indicate statistical groupings: treatments sharing letters are similar, while those with different letters are significantly different. In short, it highlights which treatments have higher or lower averages and whether those differences are meaningful.
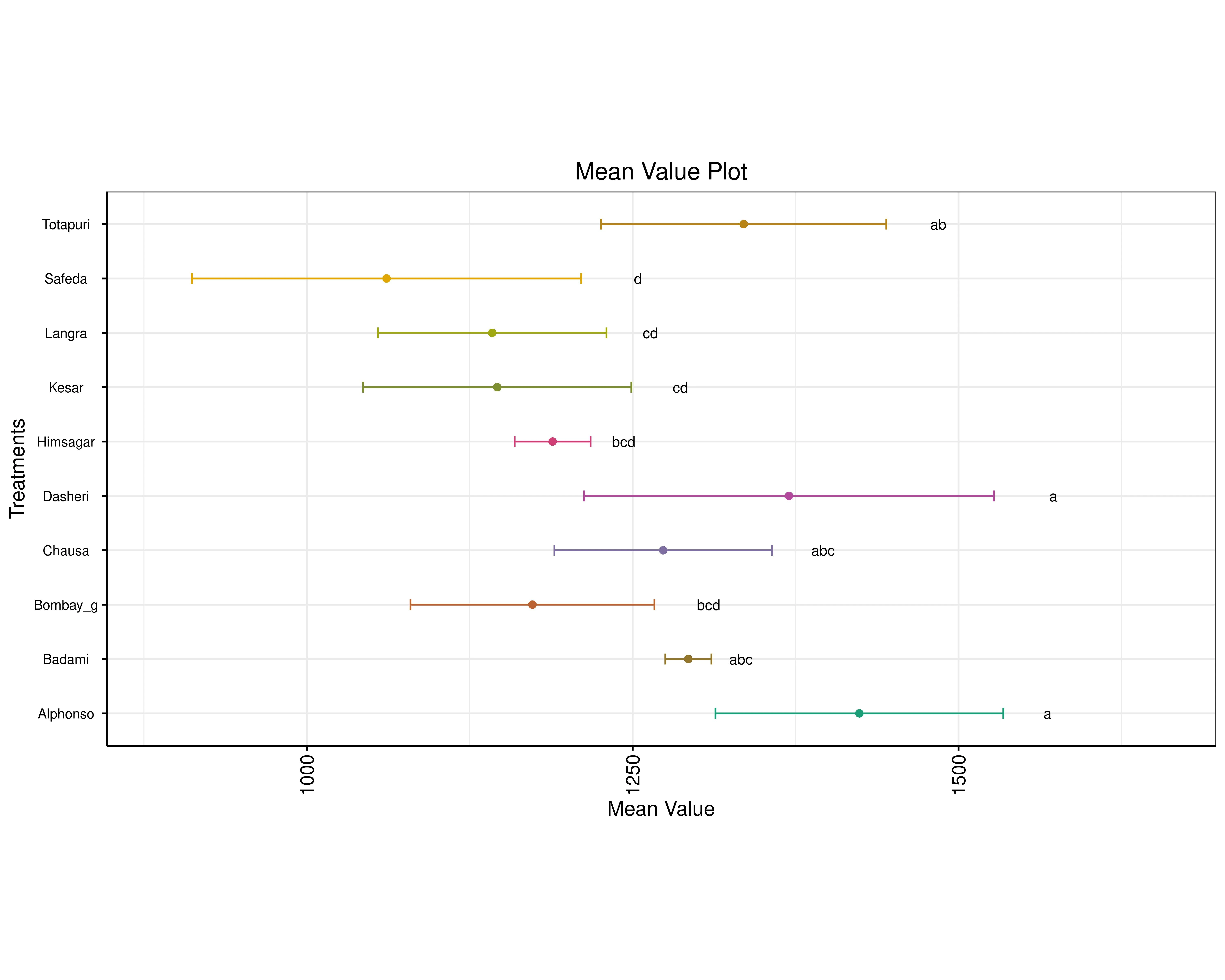
A mean value plot compares the mean values of different treatments, each shown as a colored dot with horizontal error bars indicating variability. Treatments are listed vertically, and their mean values are plotted along the x-axis. Letters next to each point represent statistical groupings: treatments sharing letters are statistically similar, while those with different letters are significantly different. This layout helps visualize which treatments have higher or lower averages and whether those differences are meaningful.
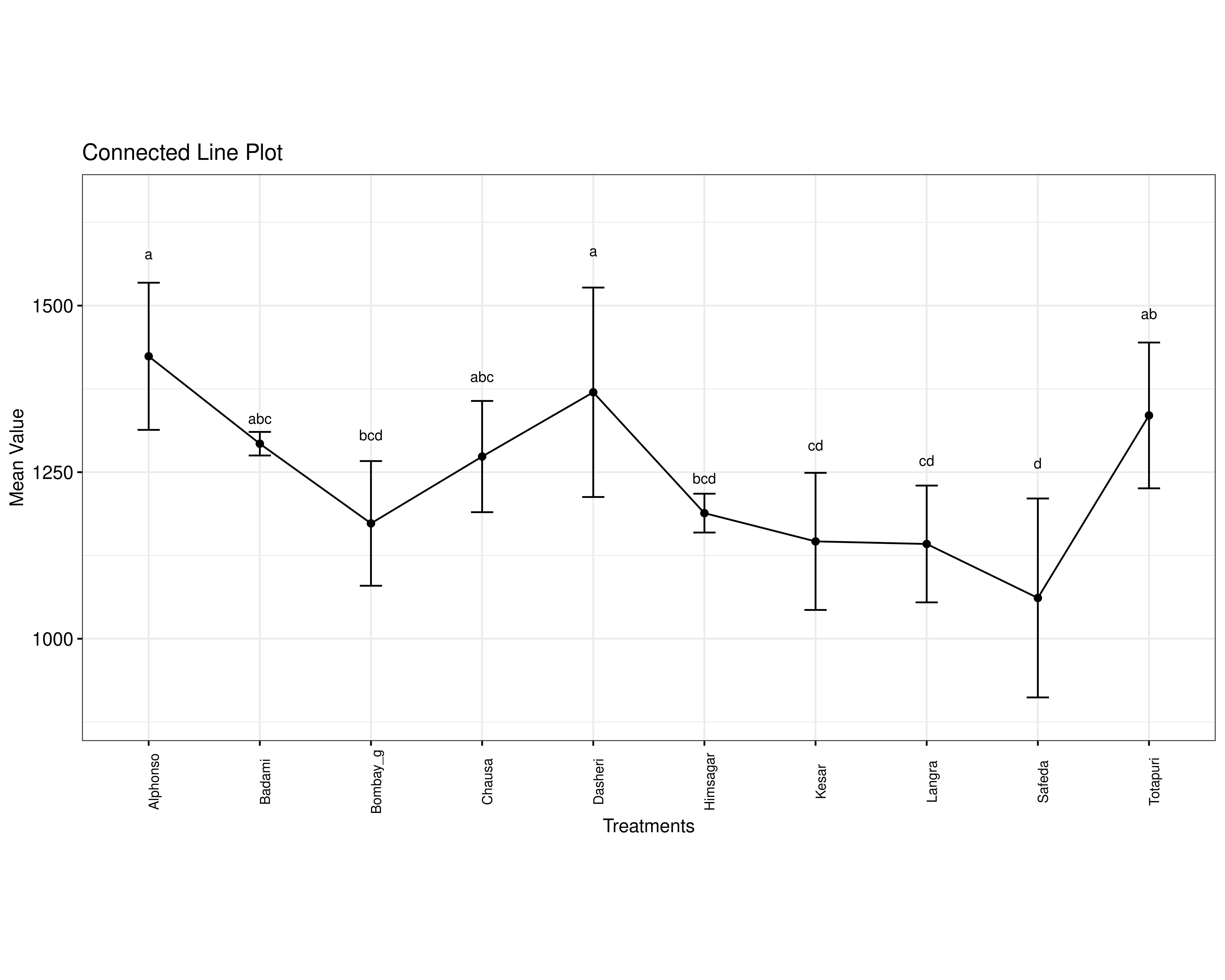
A connected line plot compares the mean values of different treatments, with each point representing a treatment’s average and error bars showing variability. The points are linked by lines to highlight trends across treatments. Above each point, letters indicate statistical groupings: treatments sharing letters are statistically similar, while those with different letters are significantly different. This plot helps visualize how treatment values change and which ones differ meaningfully from others.
12 Advanced plots
RAISINS also provides advanced plots which goes beyond basic bar charts and histograms to give deeper insight into your data, especially distributions, relationships, and deviations from expectations.(See Figure 19)
SUMMARY PLOT
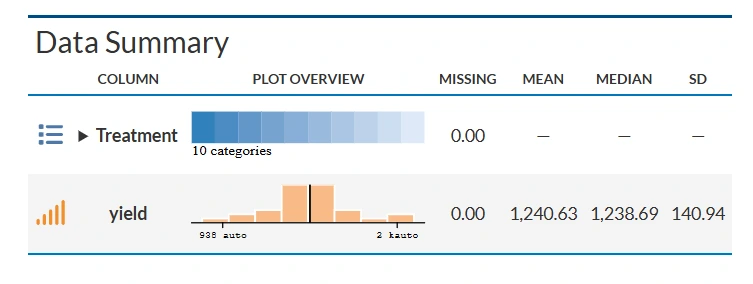
A summary plot is a visual representation that shows how data are distributed. It helps quickly understand the pattern, spread, and central tendency of the data.
ADVANCED RAINCLOUD PLOT
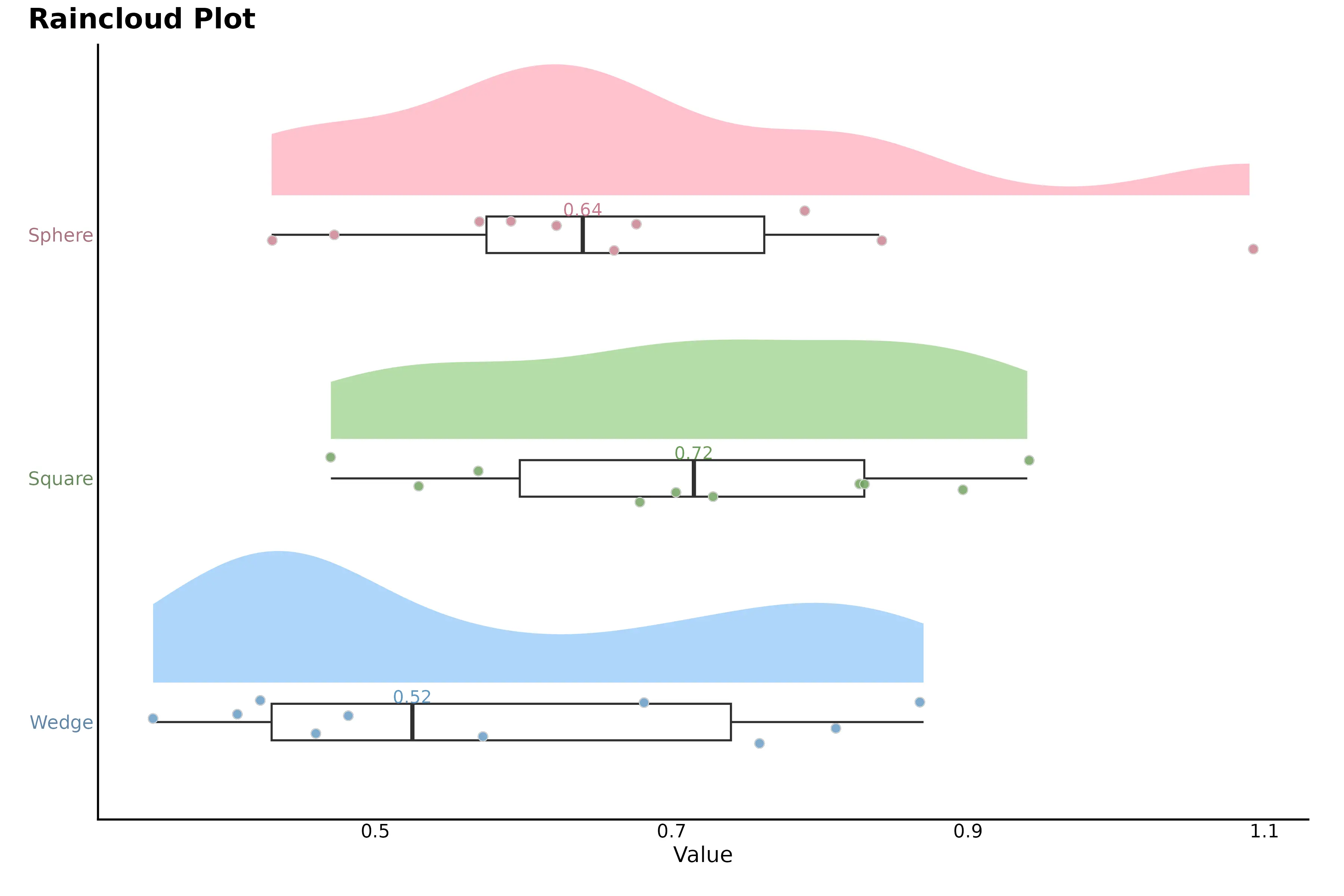
Advanced raincloud plot combines a density plot, boxplot, and individual data points to show the full distribution of each group. The colored density (“cloud”) shows where values are most concentrated, the boxplot summarizes the median and quartiles, and the dots (“rain”) represent individual observations. The numbers indicate summary values (usually mean or median), and the horizontal axis shows the measured variable.
QQ PLOT
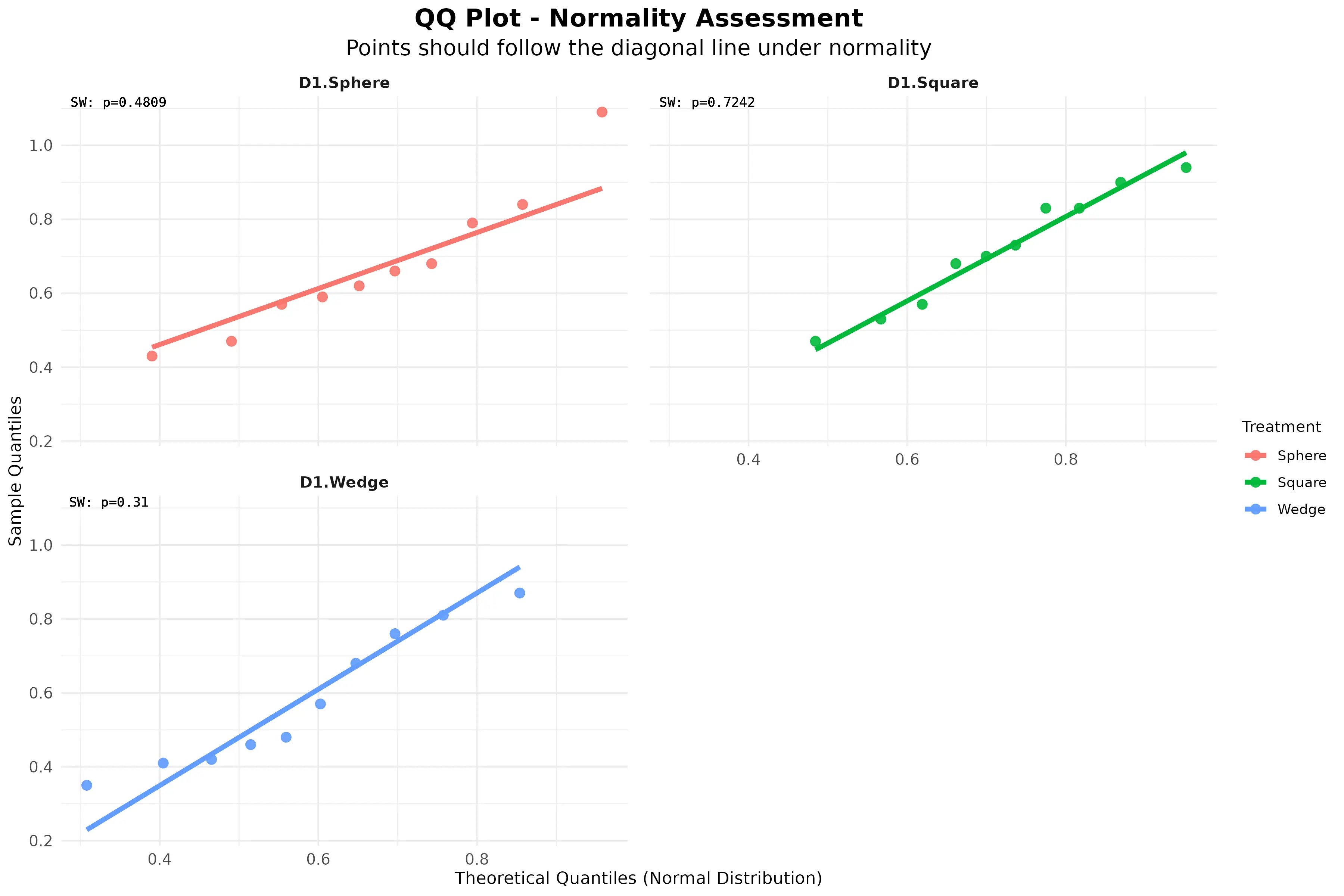
Q–Q (quantile–quantile) plot is used to assess normality of the data. The points represent observed data quantiles plotted against theoretical quantiles from a normal distribution. Because most points lie close to the diagonal reference line, the data approximately follows a normal distribution.
RAIN CLOUD PLOT
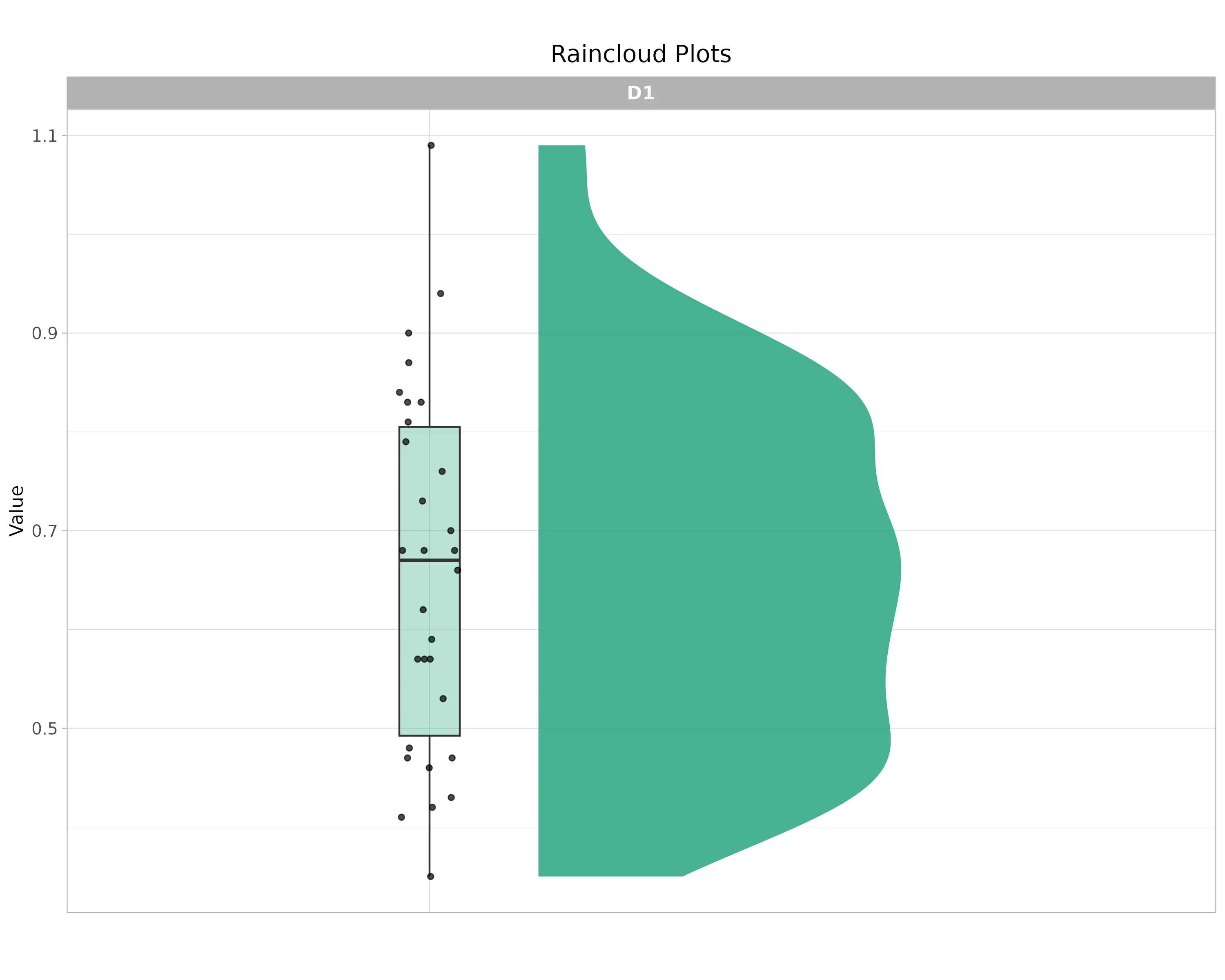
Raincloud plot shows the distribution of the response variable. The half-violin (cloud) represents the data density, indicating where values are most concentrated. The boxplot summarizes the median and interquartile range, and the jittered points (rain) show individual observations.
DISTRIBUTION PLOT

The distribution plot shows how the data values are spread for each treatment. It provides a visual comparison of the pattern, spread, and variability of observations across treatments, helping to understand overall differences and consistency in the data.
13 AI interpretation
RAISINS is equipped with an AI-powered RAISINS Assistant designed to assist users in comprehending the outcomes of statistical tests and data analysis. This functionality provides clear and concise summaries of results, identifies statistically significant differences between groups, and offers informed suggestions for potential next steps or interpretations.The user can get detailed interpretations of the analysis by clicking on AI interpretation on the Analysis as shown below Figure 25 .
14 Multivariate
Multivariate analysis in Completely Randomised Design (CRD) helps you to compare different response variables simultaneously. Remember the PCA used for multivariate selection, is an exploratory technique, not an inferential method. Now, in our example, of evaluation of ten mango cultivars - Alphonso, Kesar, Dasheri, Himsagar, Chausa, Badami, Safeda, Bombay_g, Langra, and Totapuri - by a horticultural scientist, navigate to Multivariate see Figure 26.
MANOVA and PCA will be automatically carried out based on the selected variables. MANOVA table with interpretation appears automatically. PCA results and plots will appear along with automated interpretation.
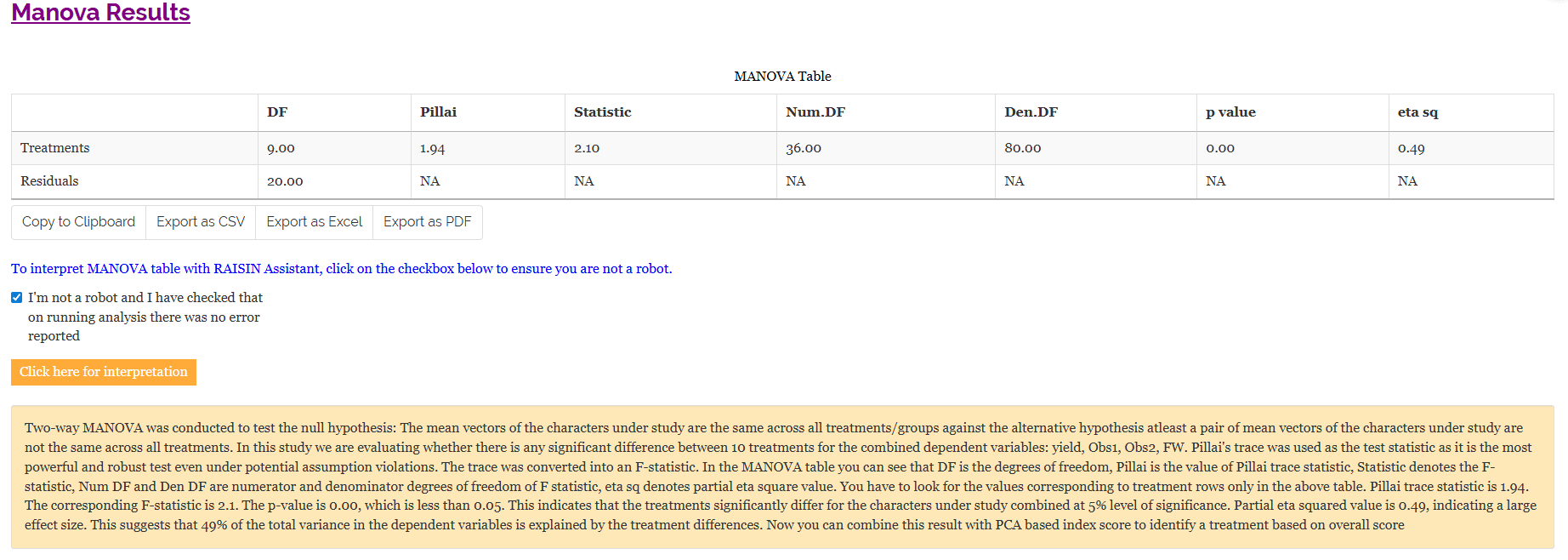
The table titled ‘Eigen Values PCA’ given Figure 28 provides information about the eigen values and the percentage of variance explained by each principal component. The principal components PC1, PC2 have eigenvalues greater than one and are considered important for further analysis. PC1 accounts for approximately 41.16% of the variance in the dataset, while PC2 accounts for about 29.5% of the variance. Together, PC1 and PC2 explain approximately 70.66% of the total variance (termed as cumulative variance). Since PC1 explains more than 40% of the variance, a PC1-based index score is a strong consideration. Additionally, since both PCs explain more than 60% of the variance in the data, an index score based on both PCs is also appropriate. The scree plot below illustrates the proportion of variance explained by each principal component.
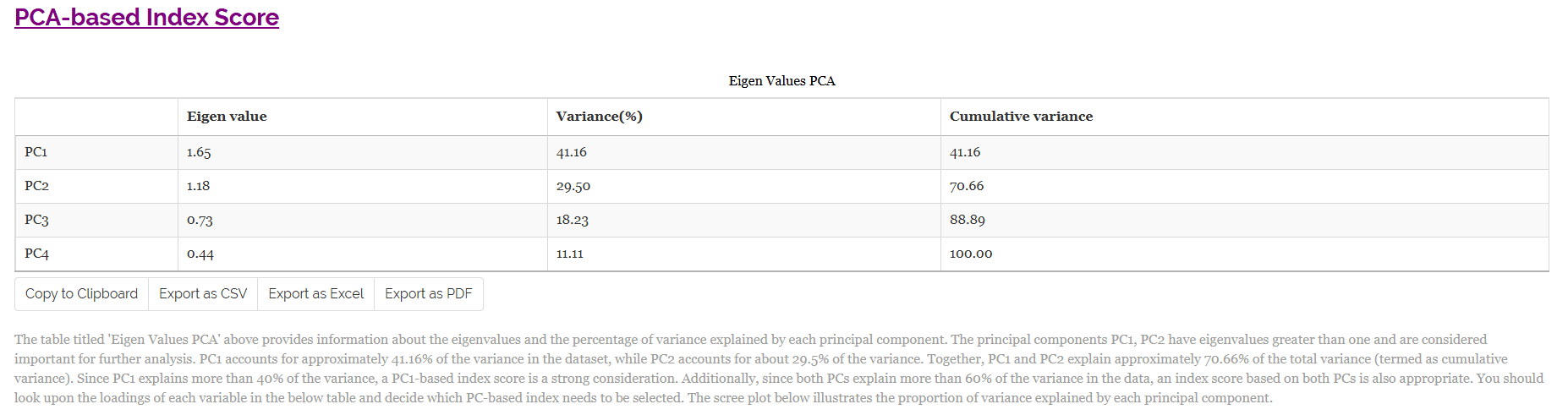
The scree plot given Figure 29 illustrates the proportion of variance explained by each principal component.
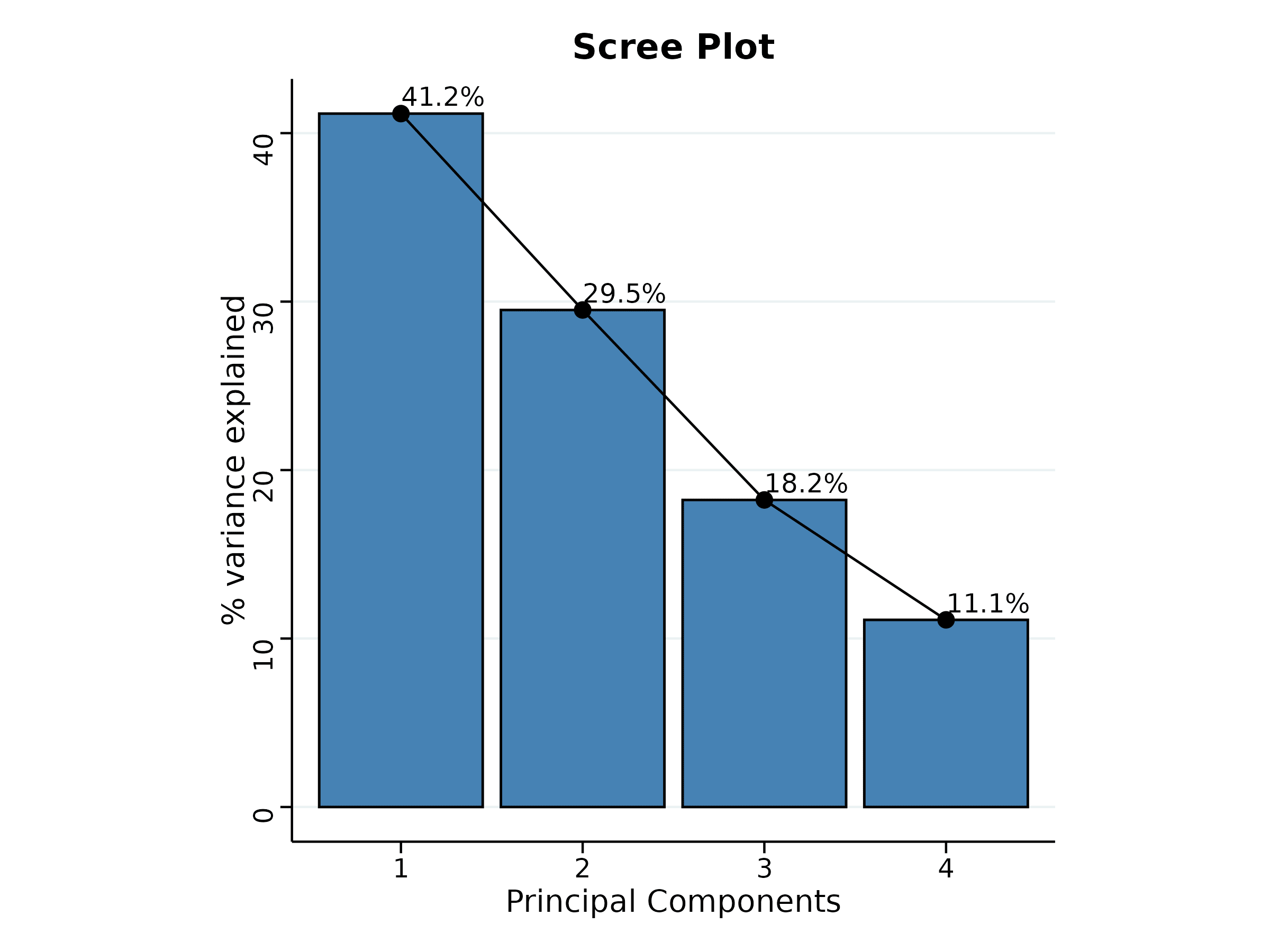
Look upon the loadings of each variable in the given Figure 30 and decide which PC-based index needs to be selected. You can see that the variables yield and Obs2 have positive loadings in PC1. If you are seeking treatments with high values for these variables, consider treatments with a high index score based on PC1. Thus, treatments with high index scores based on PC1 can be considered optimal for improving the above variables. Conversely, the variables Obs1, FW have negative loadings in PC1. If you aim to improve these variables, look for treatments with a low index score based on PC1. For PC2, the variables yield, Obs1 and FW have positive loadings. If these variables are your focus, consider an index score based on PC2. Similarly, the variables Obs2 have negative loadings on PC2, and treatments with low index scores for PC2 would be suitable for these variables. It is recommended to use variables that are highly correlated for PCA, as this helps in constructing a more reliable and meaningful index.

The biplot gives a visual representation of the relationships among variables and treatments. Treatments with high values for a specific variable are positioned in the direction of that variable. The angle between variables in the biplot indicates their correlation, smaller angles suggest high positive correlation, while larger angles close to 90 degrees suggest weak or no correlation. Thus, the biplot aids in understanding the contributions of variables to each PC and in identifying patterns among treatments.
In RAISINS, we calculate a scaled index score by converting the index score to a range of 0 to 1, making it easier to interpret and compare. This standardized approach ensures consistency in evaluating treatments based on their index scores.To refine your selection, use the ‘Select cutoff for Scaled Index Score’ feature given as in Figure 32, where you can choose the cutoff percentage to select treatments above or below a certain threshold. The default cutoff is set at 75%. By toggling the up-arrow and down-arrow buttons below the cutoff selection, you can select the top or bottom percentage of treatments as per your preference. Selected treatments are highlighted in yellow in the table below, providing a clear visual cue. Additionally, a plot based on the index scores is also displayed to aid in your analysis.
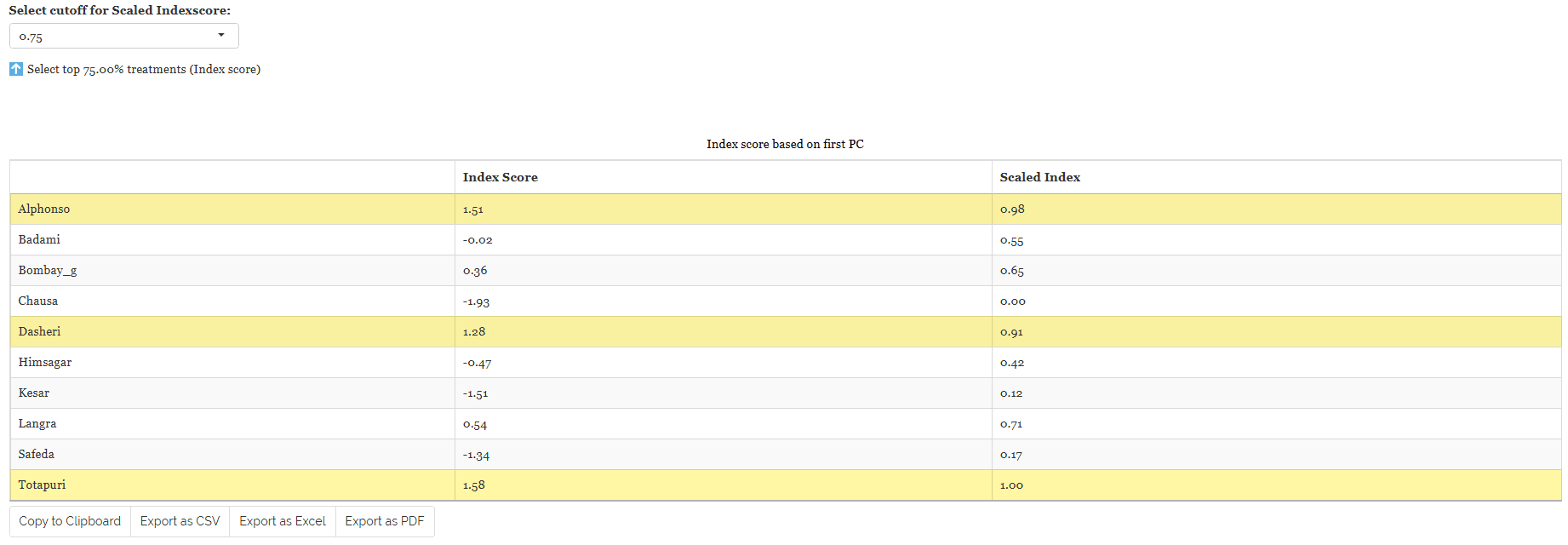
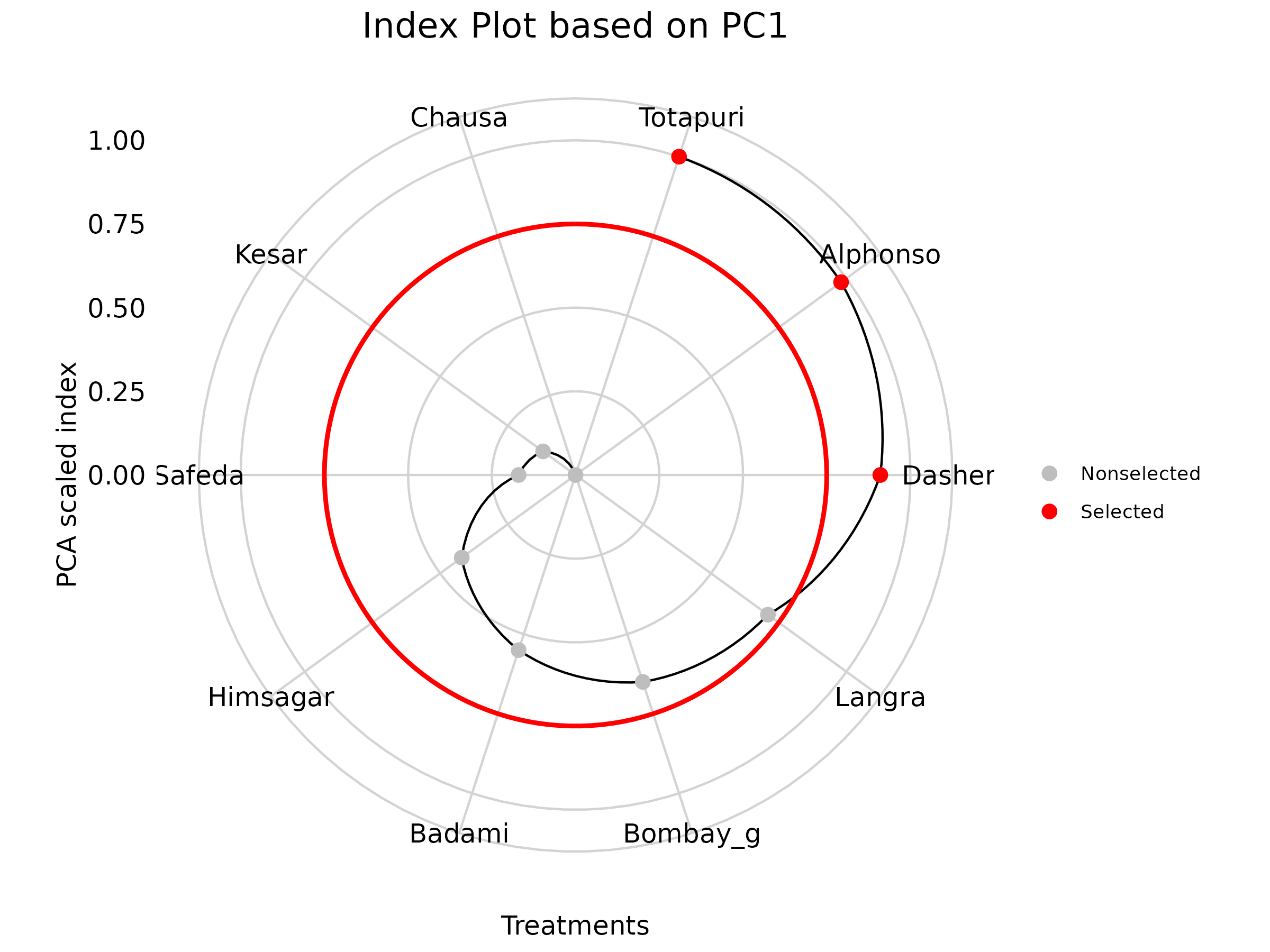
Combining all this information, the experimenter can arrive at an overall conclusion that is statistically sound and contextually relevant to their study.
15 Preparing your data
“Your analysis is only as good as your data! Feed RAISINS high-quality data, and it will deliver powerful insights feed it messy data, and the results won’t be trustworthy.”
Create your dataset in MS Excel
Build your dataset directly within the RAISINS app
16 Preparing data in MS Excel
Open a new blank sheet in MS Excel with only one sheet included, and avoid adding any unnecessary content. The dataset should follow a column-based format, where the first column represents the treatment or group to be compared-you can name this column appropriately, such as “Group” or “Treatment.” All characters under study (e.g., yield, Obs1, Obs2, FW) should be arranged in separate columns, and each group should be repeated according to the number of replications. The file can be saved in CSV, XLS, or XLSX format, but CSV is recommended as it is lighter and enables faster loading. Ensure that there are no unwanted spaces in column names or group names. For reference, see the structure shown in Figure 34. As illustrated in Figure 3, groups must appear repeatedly based on replications, and the data can also be arranged as shown in Figure 35.
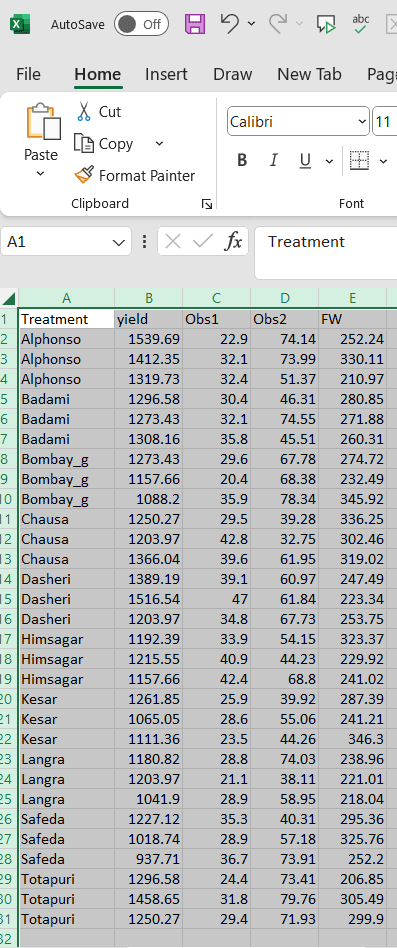
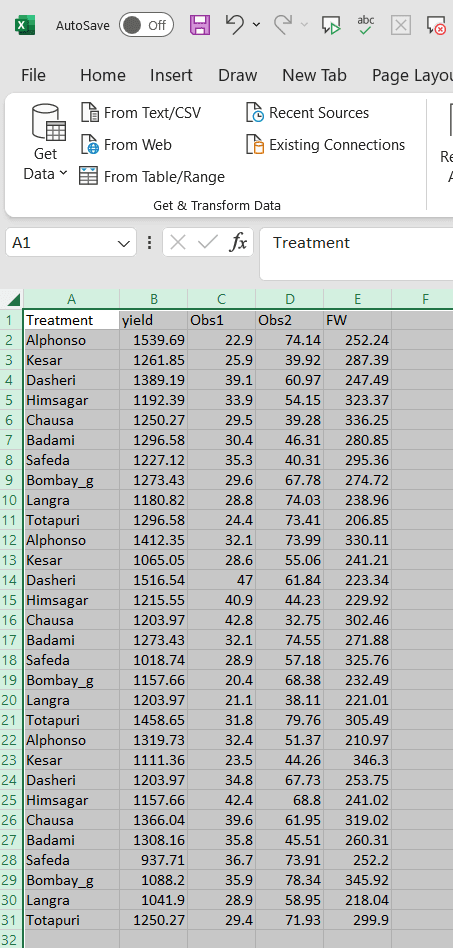
Dataset Creation Rules
1. Column Naming Convention - No spaces allowed in column names.
- Use underscores (_) or full stops (.) for separation. - Avoid symbols and special characters like %,# etc 2. Data Arrangement - Start data arrangement towards the upper-left corner.
- Ensure the row above the data is not blank. 3. Cell Management - Avoid typing or deleting in cells without data.
- If needed, select affected cells, right-click, and select Clear Contents. 4. Column Relevance - Name all columns meaningfully.
- Exclude unnecessary columns not required for analysis.
How to Save as CSV in MS Excel
1. Open Your Workbook
- Ensure your data is arranged properly with only one sheet.Click ‘File’ Menu
- Go to the top-left corner and click on File.
Choose ‘Save As’ or ‘Save a Copy’
- Select the location where you want to save your file.
Set File Type to CSV
- In the ‘Save as type’ dropdown menu, choose CSV (Comma delimited) (*.csv).
Name Your File
- Enter a relevant file name without spaces (use underscores if needed).
Click ‘Save’
- Click Save to export the file.
💡 Tip: Before saving, double-check that your data is on the first sheet and follows the required format (e.g., no empty rows above the data, meaningful column names).
17 Creating dataset in RAISINS
If you’re unsure about the correct format for creating a dataset, don’t worry - Raisins offers an option to create data directly within the app using the prescribed template. Here’s how:
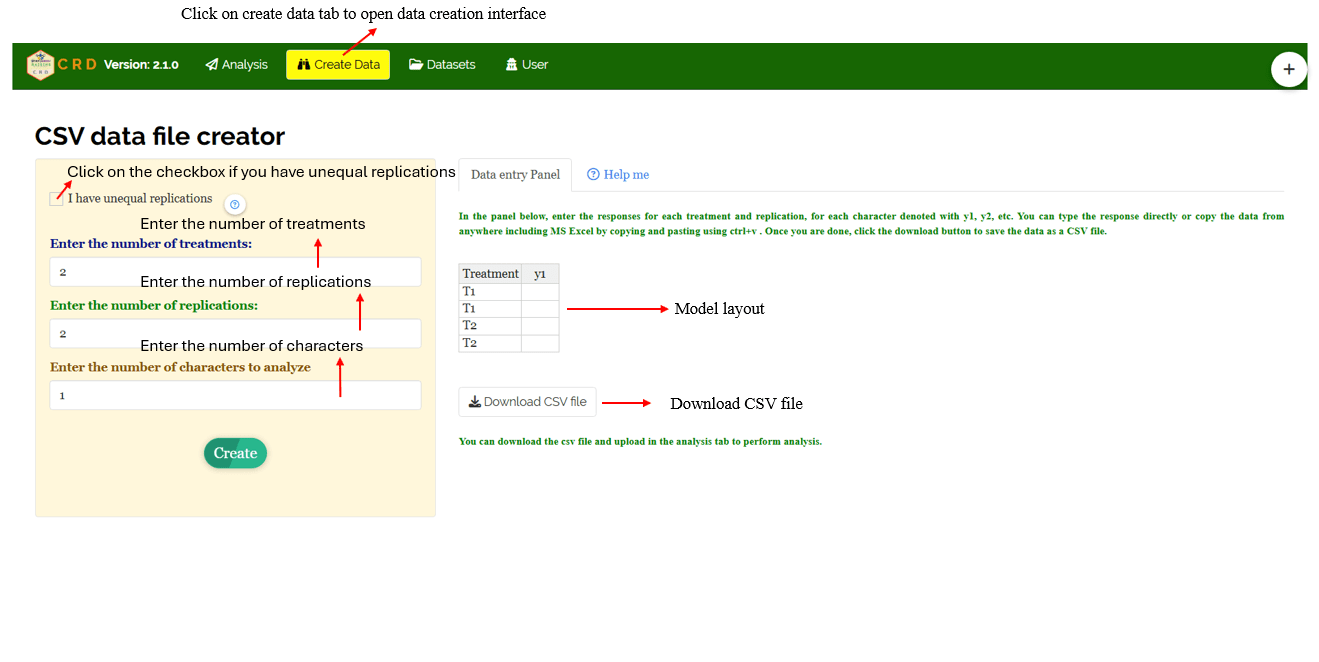
Navigate to the Create Data Tab
Select the number of Treatments
Select number of Replications
Select number of Characters
Click on Create button**
Model layout will appear as shown in Figure 36. Now you may enter the observations manually into the CSV file once downloaded, or paste the observations straight into the file provided. Once you have entered the observations in the layout, download the csv file and upload in Analysis.
18 Model datasets
To test the app or better understand the data arrangement, we provide model datasets within the app. You can download them from the Datasets.
19 FAQ’s
The app includes a dedicated FAQs to help clarify common doubts and guide users through various features. This section provides detailed answers to frequently asked questions, offering additional information and helpful tips to ensure a smooth user experience. If you’re ever unsure about how something works, the FAQs is a great place to start.

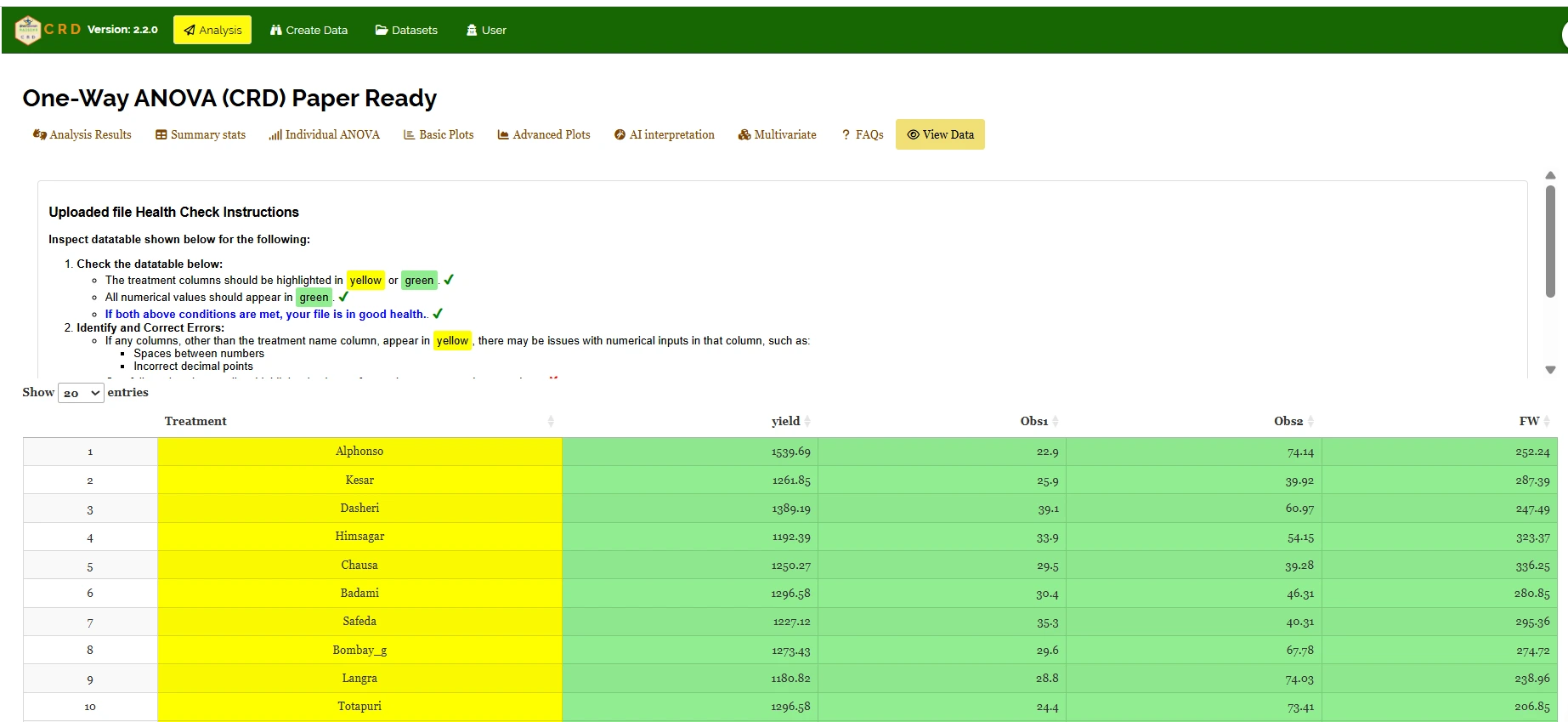
20 View data
View Data serves as the primary diagnostic tool for ensuring data integrity before analysis. Upon uploading your dataset, the system performs an automated Health Check to validate column types and formatting.